Text- und sprachbasierte Forschungsdaten nutzen und erhalten
Text+ stellt im Rahmen der NFDI einen umfangreichen Bestand an Textsammlungen und Korpora, Editionen und lexikalischen Ressourcen zur Nachnutzung bereit. Zum Angebotsportfolio gehört neben eigenen Daten und Diensten die Möglichkeit, Forschungsdaten der Community aufzunehmen und langfristig zu bewahren.
Text+ und die NFDI
Die DFG fördert im Rahmen der Nationalen Forschungsdateninfrastruktur (NFDI) insgesamt 26 Konsortien aus den vier Bereichen der Geistes- und Sozialwissenschaften, Ingenieurwissenschaften, Lebenswissenschaften und Naturwissenschaften. Der Verbund Text+ ist eines von sechs Konsortien aus den Humanities, das sind desweiteren Berd@NFDI, KonsortSWD, NFDI4Culture, NFDI4Memory, NFDI4Objects. Während es über die NFDI-Sektionen viele konsortienübergreifene Aktivitäten gibt, steht der Verbund Text+ mit den geistes- und sozialwissenschaftlichen Konsortien in besonders engem Austausch.
Showcase
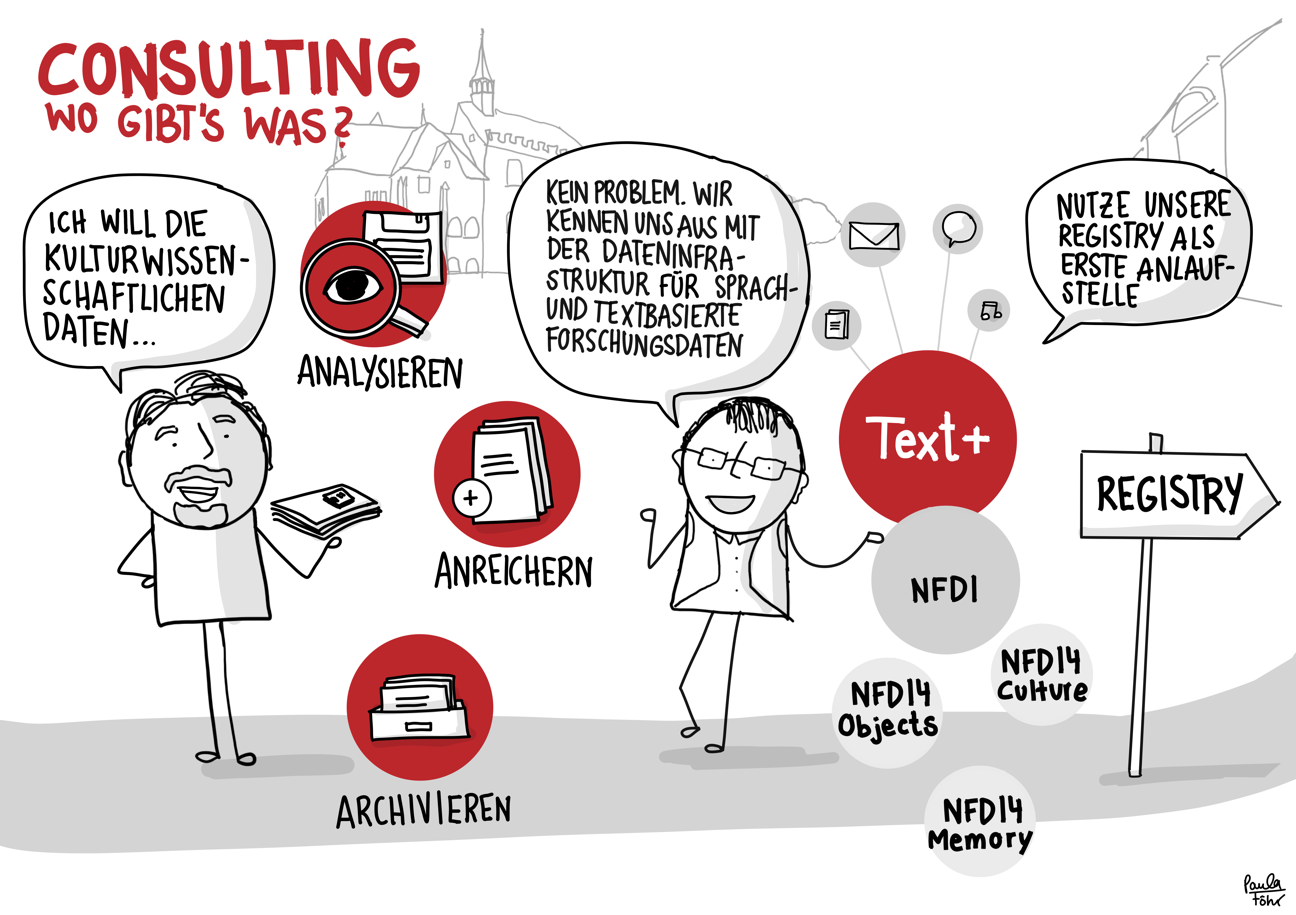
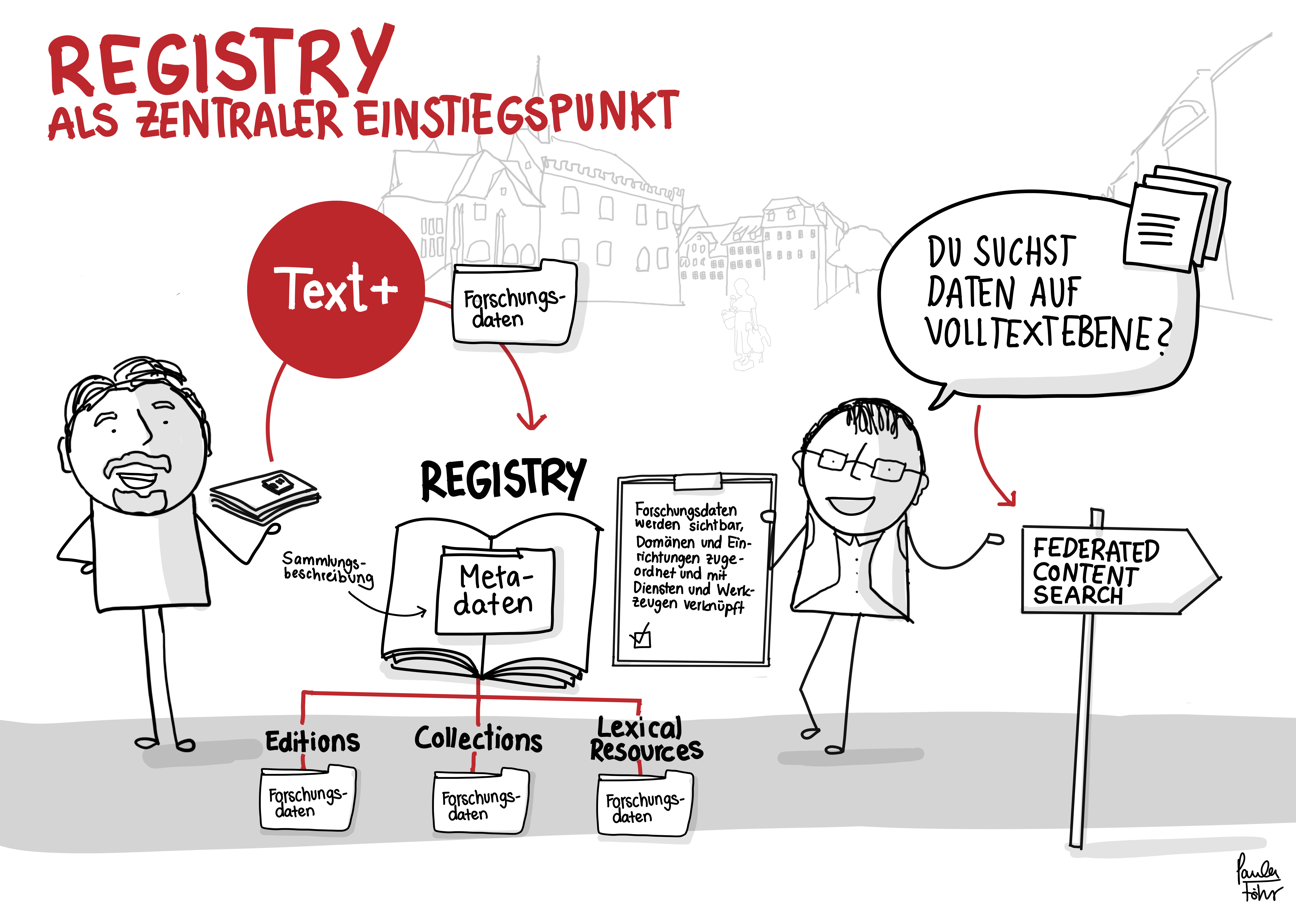
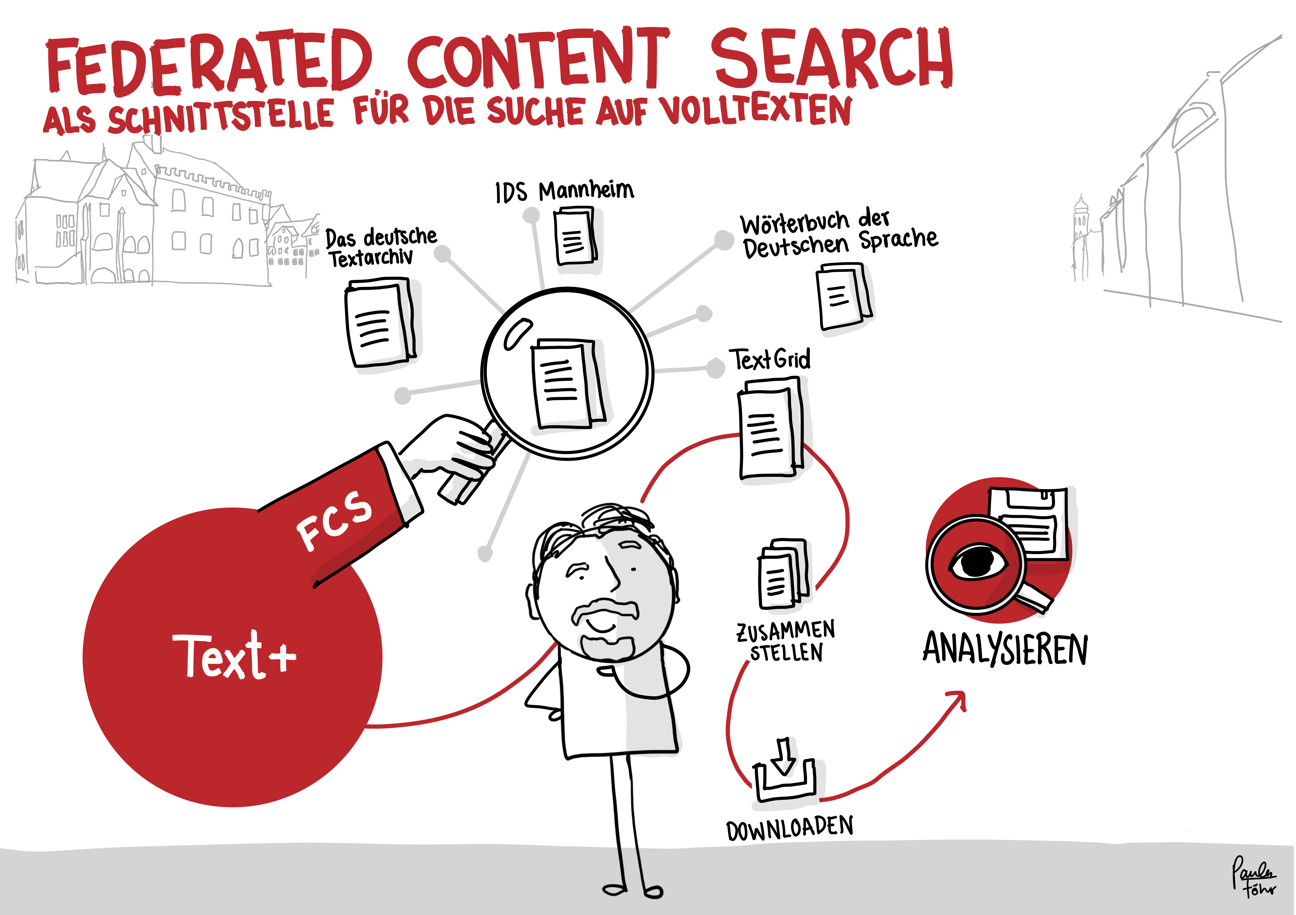
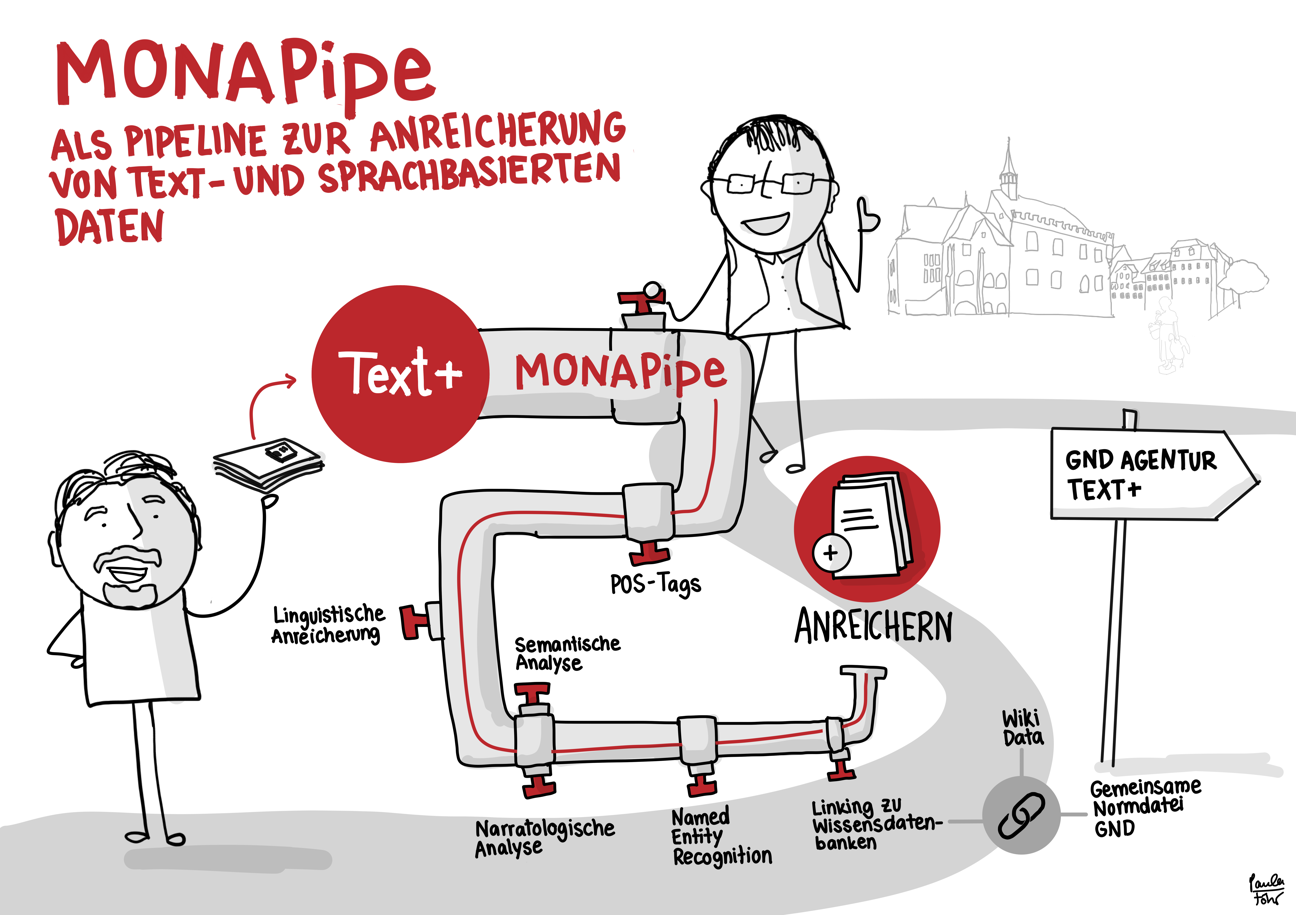
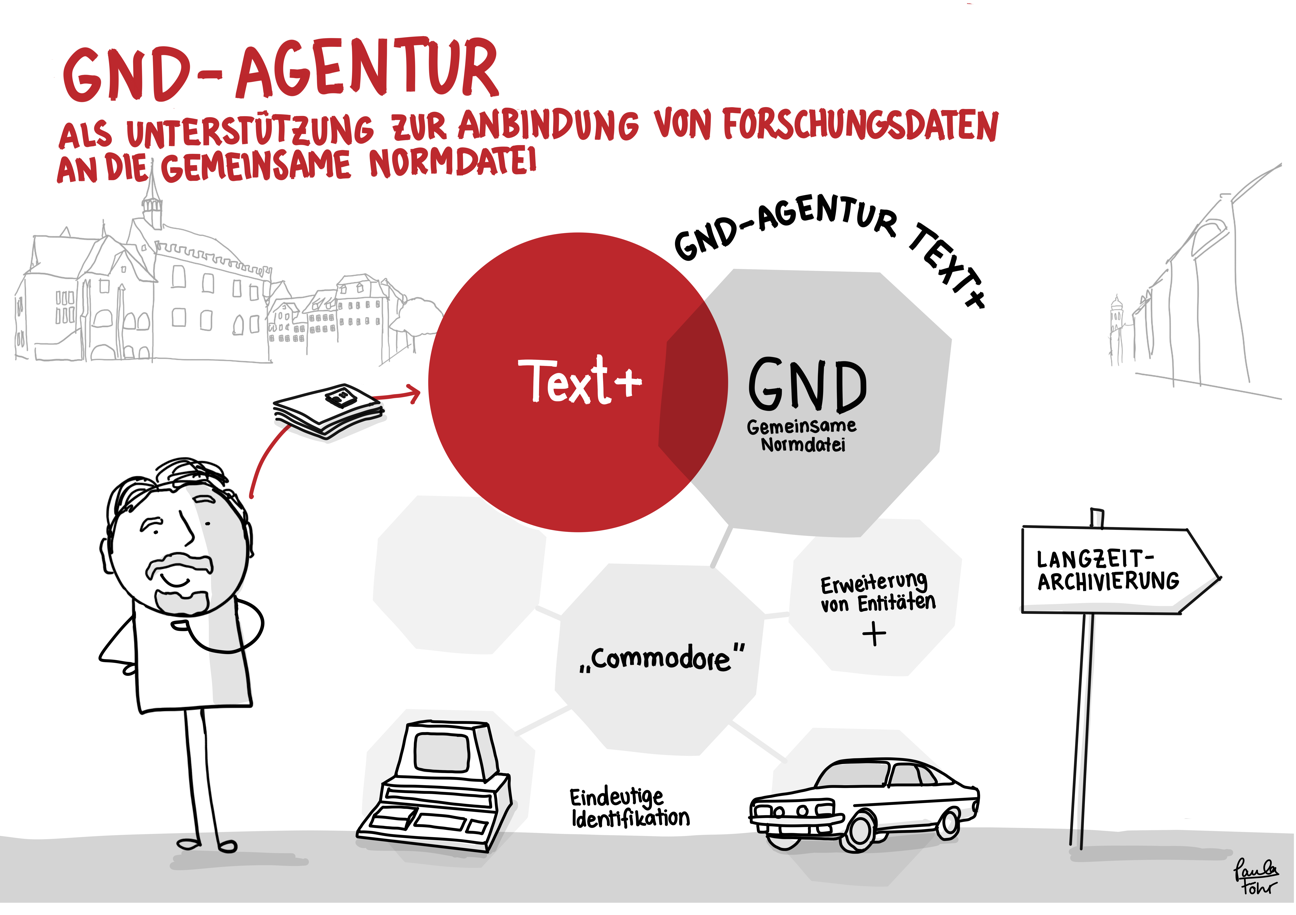
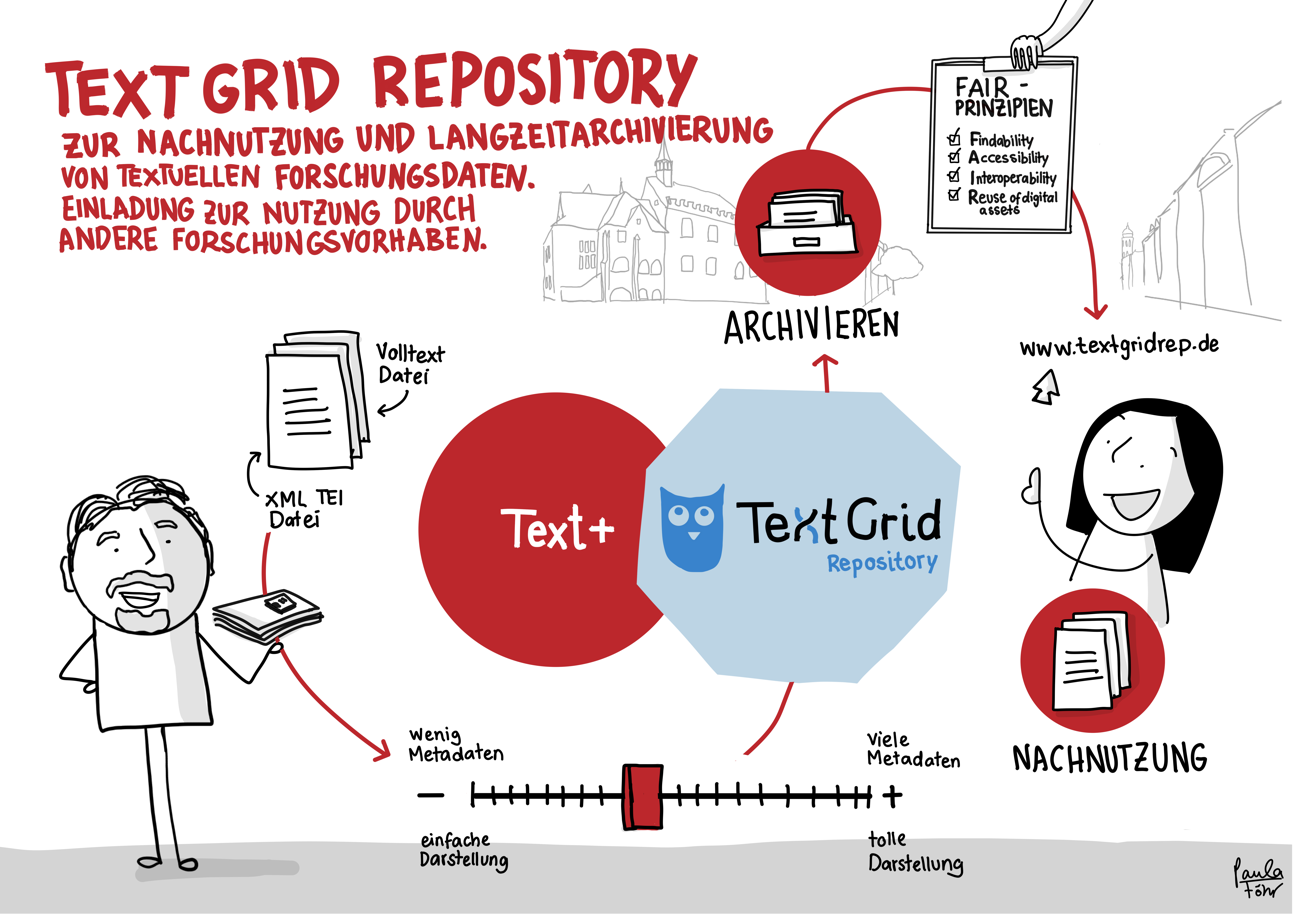
Der skizzierte Workflow bietet – am Beispiel der Übergabe von auf Disketten gespeicherten Forschungsdaten – einen Eindruck der Datenintegration in Text+. Er reicht vom Erstkontakt über das Consulting bis hin zur Aufnahme, Nachnutzbarmachung und langfristigen Bewahrung der Daten (Registry, FCS, MonaPipe, GND-Agentur, TextGrid Repository).