
Herzlich willkommen!
Wir freuen uns, Euch und Ihnen den ersten Text+ Newsletter präsentieren zu können. Zukünftig werden wir in dieser Rubrik maximal viermal im Jahr Neuigkeiten aus dem Projektgeschehen mitteilen. Wir freuen uns über Feedback, Fragen oder Wünsche. Diese erreichen uns am einfachsten über das Office (office@text-plus.org).
Warum ein Newsletter?
Text+ als NFDI-Konsortium hat die Nutzung und den Erhalt text- und sprachbasierter Forschungsdaten zum Ziel. Dafür werden in der Projektlaufzeit in Zusammenarbeit mit der Community Angebote entwickelt und aufgebaut. Wo immer es sinnvoll und möglich ist, greifen wir auf bereits vorhandene Vorarbeiten zurück oder arbeiten mit anderen NFDI-Konsortien zusammen. Neben der Information über ganz konkrete Services und Ressourcen möchten wir, unter anderem mit dem Instrument Newsletter, über den aktuellen Arbeitsstand informieren. Nicht zuletzt möchten wir damit auch deutlich machen, dass Text+ an dem Feedback und der Beteiligung der Community interessiert ist.
Highlights aus dem Blog
In dieser Rubrik stellen wir interessante Beiträge aus dem Text+ Blog vor. Das Blog informiert rundum Text+ und stellt - in Ergänzung zur Webseite - auch Work in Progress vor oder erlaubt einen detaillierteren Blick auf individuelle Themen. Alle Beiträge sind mit DOIs versehen und zitierbar.
Text+Plus, #05: Von abejcejaŕ bis źurja: Integration niedersorbisch-deutscher Wörterbücher im Kooperationsprojekt INSERT
Mit INSERT hat ein Text+ Kooperationsprojekt aus der ersten Runde einen schönen und informativen Blogpost zu den erzielten Ergebnissen nach einem Jahr Arbeit vorgelegt. Mit dem dedizierten Kooperationsprojekt namens INSERT wurden in 2023 nun vier der wichtigsten niedersorbisch-deutschen Wörterbücher zunächst in das Standardformat TEI Lex-0 übersetzt, um anschließend in die digitalen Infrastrukturen von Text+ integriert zu werden, insbesondere der föderierten Inhaltssuche des NFDI-Konsortiums. Das Projekt ist der Datendomäne Lexikalische Ressourcen zugeordnet.
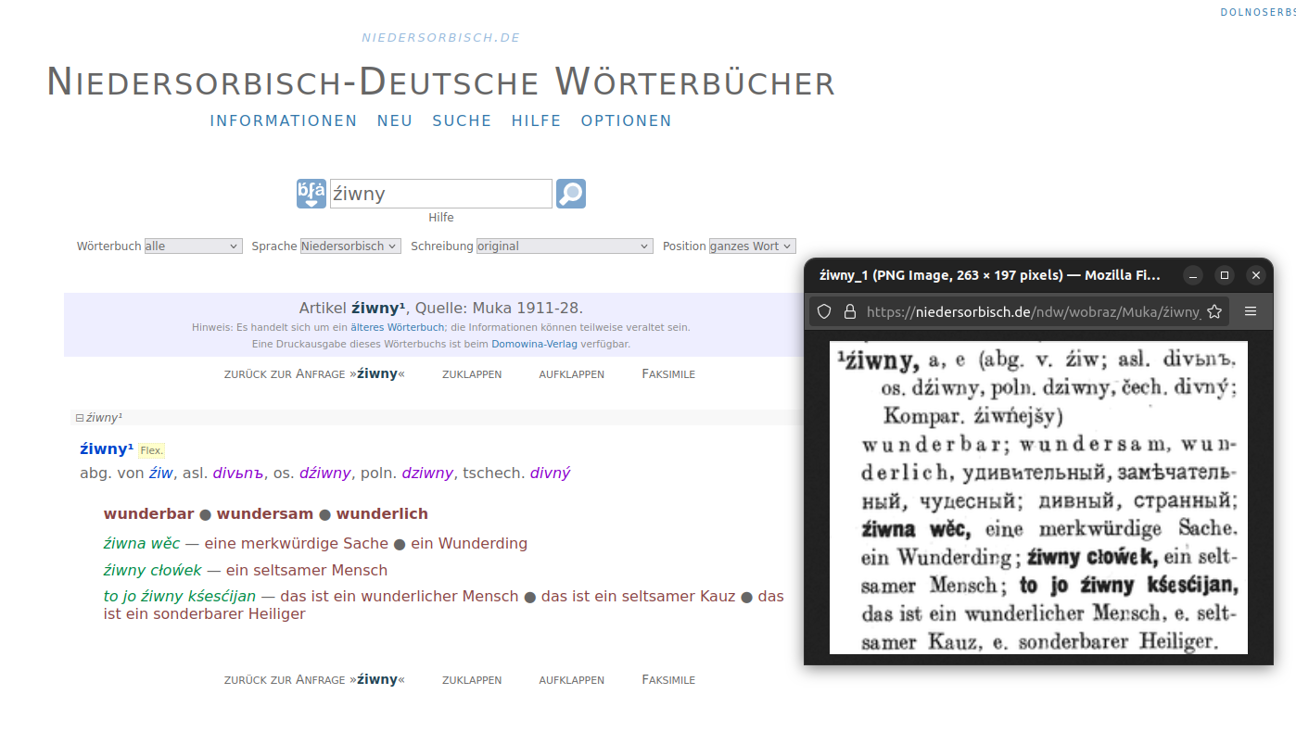
Nach der erfolgreichen Erstellung der gemappten Daten konnten diese in die digitalen Infrastrukturen von Text+ integriert werden. Hierfür wurden zunächst passende Metadaten erstellt, inklusive der Registrierung persistenter Handles. Dies ermöglichte eine Aufnahme der Ressourcen in das Repositorium der Sächsischen Akademie der Wissenschaften zu Leipzig (SAW), eines der Datenzentren für lexikalische Ressourcen des NFDI-Konsortiums. Im SAW-Repositorium werden die Ressourcen archiviert und, soweit es ihre Lizenzen erlauben, direkt zum Download angeboten. Dank der Bereitstellung der Metadaten über das OAI-PMH-Protokoll können sie außerdem in verschiedenen Aggregatoren entdeckt werden.
Um zu gewährleisten, dass auch zukünftige Updates der Repräsentationen der Wörterbücher ihren Weg in die Infrastrukturen finden, wurde zudem ein git-basierter Ingest-Workflow entwickelt, mit welchem festgehaltene Neuerungen automatisch getestet und als dedizierte Releases in das SAW-Repositorium als separate Versionen eingepflegt werden können.
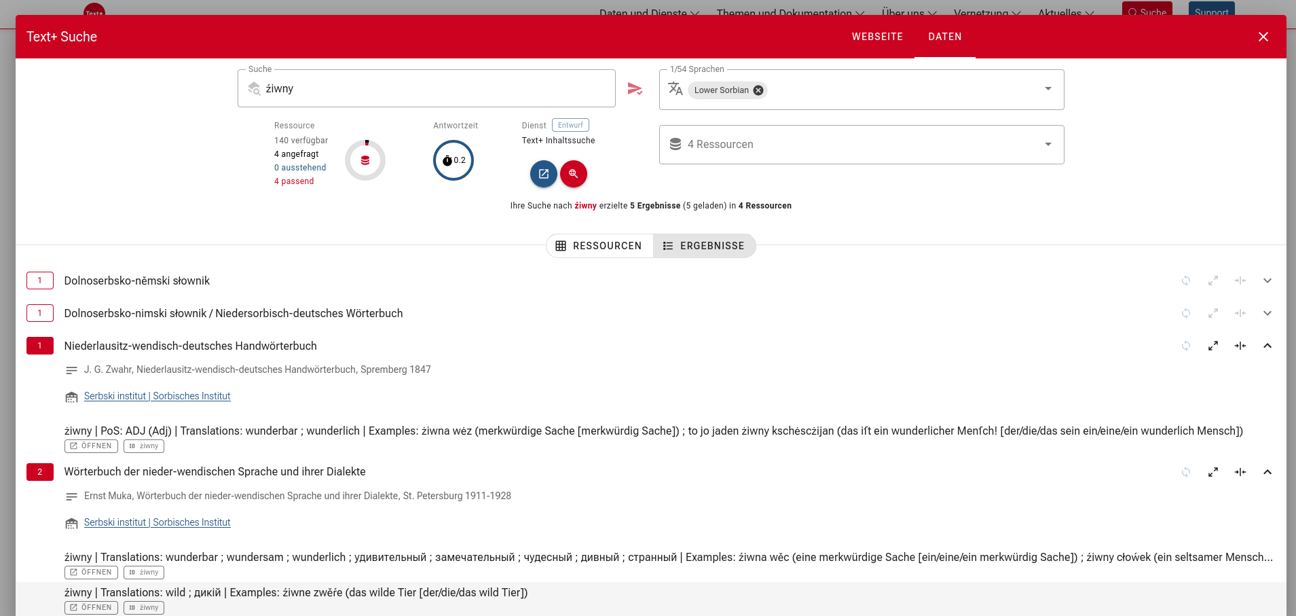
Eine weitere wichtige Anbindung ist der Import der Daten in einen von der SAW bereitgestellten Endpunkt der föderierten Inhaltssuche in Text+ (Federated Content Search, FCS). Hierfür wurden Kerninformationen der vorliegenden TEI Lex-0-XML-Daten via XSLT transformiert und dem Endpunkt übergeben. Der Mehrwert dieses Imports? Über Harvester wie der Suchmaske auf dem Webportal von Text+ stehen die vier Wörterbücher nun als Ressourcen zur Verfügung, deren Inhalte mit einer differenzierten Anfragesprache (Erik Körner et al.: „Federated Content Search for Lexical Resources (LexFCS): Specification“. Zenodo 2023. DOI: 10.5281/zenodo.7986303) durchsucht werden können.
Diesen Blogbeitrag zitieren: Felix Helfer (2024, 4. April). Text+Plus, #05: Von abejcejaŕ bis źurja: Integration niedersorbisch-deutscher Wörterbücher im Kooperationsprojekt INSERT. Text+ Blog. Abgerufen am 23. April 2024, von https://doi.org/10.58079/w5xm
Partner-Parade #02: Der Hut der Deutschen Nationalbibliothek im Text+ Konsortium hat drei Ecken
Der Beitrag stellt die dreifache Rolle der Deutschen Nationalbibliothek (DNB) im Text+ Konsortium und ihre Arbeitsschwerpunkte vor. Die DNB ist nicht nur federführende Institution der Datendomäne Collections sowie eines von deren elf zertifizierten Daten- und Kompetenzzentren, sondern stellt auch in Zusammenarbeit mit den Partnern die Infrastruktur für die Gemeinsame Normdatei (GND) zur Verfügung. Im Folgenden der Ausriss aus dem Blogartikel zur Datendomäne Sammlungen.
„Collections“ ist eine von drei Datendomänen in Text+ und fokussiert auf Sammlungen geschriebener, gesprochener oder gebärdeter Sprache und auf Texte, die auf Grundlage wissenschaftlicher Kriterien erstellt wurden. Die Koordination der Datendomäne Collections liegt bei der DNB.
Sie verantwortet den Aufbau der verteilten Infrastruktur in der Datendomäne, etwa durch die Vernetzung von elf zertifizierten Daten- und Kompetenzzentren, die jeweils inhaltlich oder auf bestimmte Datentypen spezialisiert sind. Diese Zentren, zu denen auch die DNB selbst gehört, stellen einerseits ein breites Portfolio an text- und sprachbasierten Forschungsdaten zur Verfügung, bieten zum anderen aber auch einen Archivierungsservice für einschlägige Daten aus Forschungsprojekten an und bringen diese in die Infrastruktur von Text+ ein, wodurch sie eine höhere Sichtbarkeit erhalten und für die Wissenschaftscommunity nachnutzbar werden.
Ein zentraler Baustein in der Architektur des Projekts ist die Text+ Registry. Dabei handelt es sich um ein Nachweissystem, das die Ressourcen in Text+ auffindbar macht, miteinander vernetzt und die Anschlussfähigkeit an andere Infrastrukturen (z.B. EOSC, OPERAS und natürlich innerhalb der NFDI) gewährleistet. Unter Federführung der DNB wurde in der Datendomäne Collections ein gemeinsames Datenmodell entwickelt, mit dem alle Datenzentren die Sammlungen, die sie in die Text+ Infrastruktur einbringen, einheitlich beschreiben können. Großer Wert wurde dabei auf den Einsatz kontrollierter Vokabulare und Normdaten wie der GND (siehe unten) gelegt, denn sie erhöhen den Grad der Vernetzung und Interoperabilität der Sammlungen untereinander, aber auch zu den lexikalischen Ressourcen und Editionen in der Registry.
Viele der Sammlungen sind auch im Volltext durchsuchbar. Mit der Federated Content Search (FCS, hier der Prototyp) bietet Text+ einen zentralen Sucheinstieg, über den Forschende Volltext- und auch komplexe Suchen in aktuell mehr als 50 Ressourcen gleichzeitig vornehmen können – eine enorme Zeitersparnis bei der Zusammenstellung von Korpora und eine Erweiterung des Suchraums um Quellen, die ohne diese zentrale Suche vielleicht übersehen würden. Ein Beitrag, den die DNB zur FCS bereits geleistet hat, ist das Deutsche Zeitungsportal, dessen 20 Millionen historische Zeitungsseiten nun über die FCS durchsucht werden können. Im nächsten Schritt werden die Titeldaten der DNB und perspektivisch auch umfangreiche Volltextsammlungen wie die freien Online-Hochschulschriften an die FCS angeschlossen.
Diesen Blogbeitrag zitieren: Barbara Fischer, Philippe Genêt und Gianna Iacino (2024, 31. Januar). Partner-Parade #02: Der Hut der Deutschen Nationalbibliothek im Text+ Konsortium hat drei Ecken. Text+ Blog. Abgerufen am 23. April 2024, von https://doi.org/10.58079/vq7y
Werkstattberichte
Text+ Architektur
Die Task Area Infrastructure Operations präsentierte während des Frühjahrstreffens in der Deutschen Nationalbibliothek die Text+ Architektur in Version 1.0. Diese bietet eine funktionale Sicht auf Text+ und zeigt wesentliche technische Komponenten entlang ihrer Funktionen. Es handelt sich nicht um eine umfassende Darstellung aller technischen Komponenten oder APIs und sie bildet auch nicht alle Datenwege genau ab, sondern konzentriert sich auf die Funktionalität. Langfristig soll die Architektur dazu beitragen, die Weiterentwicklung von Text+ in der NFDI gemeinsam zu diskutieren. Insbesondere sind die anderen Konsortien mit geistes- und kulturwissenschaftlichen Zielgruppen für Text+ von Bedeutung. Aber auch andere Infrastrukturkontexte wie die Basisdiensteinitiative Base4NFDI oder der SSH Open Marketplace sind von Anfang an in der Architektur berücksichtigt.
Die Text+ Architektur ist Gegenstand ständiger Weiterentwicklung und wird nach einem gemeinsamen Treffen der Coordination Committees am 3. Juni in einer Version 1.1 bereitgestellt werden.
Text+ Kooperationsprojekte
Text+ Kooperationsprojekte Förderung 2023
2023 wurden in der ersten Förderrunde von Text+ zehn vielversprechende und innovative Kooperationsprojekte unterstützt. Die Förderung startete im Januar 2023 und lief bis zum Ende des Jahres. Die geförderten Projekte deckten eine breite Palette von Themen ab:
- Pessoa digital (Universität Rostock) zur nachhaltigen Gestaltung der digitalen Ausgabe „Fernando Pessoa. Projekte und Veröffentlichungen“ mit anschließender Integration in die Text+ Forschungsdateninfrastruktur.
- edition2LD (Heidelberger Akademie der Wissenschaften) zur Erarbeitung eines Workflows für die Modellierung von Texteditionsdaten als Linked (Open) Data im Resource Description Format. Weitere Informationen zum Projekt finden Sie hier.
- FriVer+ (Leibniz-Institut für Europäische Geschichte) zur Bereitstellung von (Meta‑)Daten zu mehr als 1800 frühneuzeitlichen bi- und multilateralen europäischen Friedensverträgen im standardisierten und nachnutzbaren XML/TEI-Format. Weitere Informationen zum Projekt finden Sie hier.
- INSERT (Sorbisches Institut) zur Integration von vier niedersorbisch-deutschen Wörterbüchern in die Text+ Forschungsinfrastruktur Weitere Informationen zum Projekt finden Sie hier.
- CGLO (Bayerische Akademie der Wissenschaften) zur Umwandlung des Nachschlagewerkes Corpus Glossariorum Latinorum (veröffentlicht 1862-1923 in 7 Bänden) in eine lemmatisierte Datenbank mit Integration in die Text+ Forschungsinfrastruktur.
- MWB-APIplus (Arbeitsstelle Trier für das Mittelhochdeutsche Wörterbuch der Akademie der Wissenschaften und der Literatur | Mainz und Arbeitsstelle Göttingen für das Mittelhochdeutsche Wörterbuch der Niedersächsischen Akademie der Wissenschaften zu Göttingen) zur Schaffung einer technischen Schnittstelle für das Mittelhochdeutsche Wörterbuch mit Integration in das Text+ Datenportfolio. Weitere Informationen zum Projekt finden Sie hier.
- KOLIMO+ (Universität Bielefeld) zur Optimierung und Anreicherung des Korpus der literarischen Moderne mit anschließender Integration in die Text+-Services.
- DiPA+ (Deutsches Institut für Erwachsenenbildung Leibniz-Zentrum für Lebenslanges Lernen e. V.) zur Integration der retrodigitalisierten Bestände des Digitalen Programmarchivs deutscher Volkshochschulen in die Text+-Infrastruktur.
- DLA Data+ (Deutsches Literaturarchiv Marbach) zur Bereitstellung eines offenen Zugangs zu den Daten des Deutschen Literaturarchivs Marbach für nachhaltige Nachnutzung über die Infrastruktur von Text+. Weitere Informationen zum Projekt finden Sie hier.
- Diskmags (Bergische Universität Wuppertal) zur Entwicklung der Re-Digitalisierungs-Methoden für Texte deutschsprachiger Diskettenmagazine und Formulierung von Best Practices für die digitale Textrekonstruktion aus alten Dateiformaten.
Wir danken allen Projekten für die Zusammenarbeit während des Förderzeitraums! Die Vielfalt der Themen und die erreichten Meilensteine spiegeln das Engagement und die Expertise aller Beteiligten wider. Wir freuen uns darauf, die Ergebnisse dieser Projekte in der Text+ Forschungsdateninfrastruktur zu sehen und die Erkenntnisse in der wissenschaftlichen Gemeinschaft zu teilen.
Text+ Kooperationsprojekte Förderung 2024
Ab dem 1. Januar 2024 begann die Förderung von neuen Kooperationsprojekten. Im Frühjahr 2023 wurden 19 vielfältige und spannende Projekte mit einem Förderbedarf von insgesamt 1 Mio. Euro eingereicht, die sich alle durch eine hohe Qualität auszeichneten. Da diese Summe das verfügbare Budget um das Vierfache überstieg, musste eine Auswahl getroffen werden, auch wenn dies keine leichte Entscheidung war. Insgesamt wurden vier Projekte zur Förderung ausgewählt, die wir bei Text+ herzlich begrüßen:
- Projekt “The Beria Collection in the Language Archive Cologne: Expansion, revision and evaluation of a data collection of an under-described African language” eingereicht von Prof. Dr. Birgit Hellwig, Dr. Isabel Compes (Universität zu Köln, Institut für Linguistik) in der Task Area Collections.
- Projekt “Thesaurus Linguae Aegyptiae – More Fair with APIs” eingereicht von Dr. Daniel Werning (Berlin-Brandenburgische Akademie der Wissenschaften, Zentrum Grundlagenforschung Alte Welt) in der Task Area Lexikalische Ressourcen.
- Projekt „Das älteste Görlitzer Stadtbuch 1305-1416: Transformation, Kuratierung und doppelte digitale Publikation (Daten, Webanwendung) einer außergewöhnlichen Buchedition für die historischen Disziplinen“ eingereicht von Prof. Dr. Patrick Sahle, Dr. Christian Speer (Bergische Universität Wuppertal / Martin-Luther-Universität Halle-Wittenberg) in der Task Area Editionen.
- Projekt „Werkzeugunterstützung für die automatische Extraktion von Tabellendaten aus historischen Zeitungen“ eingereicht von Prof. Dr.-Ing. Frank Krüger (Hochschule Wismar) in der Task Area Infrastruktur/Betrieb.
Publikationen, Services & Infoangebote
Text+ pflegt seine Bibliographie bei Zotero und stellt auf seinem Portal eine strukturierte Ansicht dar.
Onboarding-Guide der Datendomäne Editionen
Vorstellen möchten wir den Onboarding Guide, den die Datendomäne Editionen veröffentlicht hat:
- Hensen, K. E., Speer, A., Geißler, N., Sievers, M., Kudella, C., Lemke, K., & König, S. (2024). Onboarding Guide der Task Area Editions (Version v1). Zenodo. https://doi.org/10.5281/zenodo.10854729
Der Onboarding Guide stellt, nach Angeboten gegliedert, dar, wie sich Einrichtungen und Forschende einbringen können. Konkret bspw. die Frage nach der Integration von neuen Datenbeständen in das Text+ Portfolio.
Förderzusage für Jupyter4NFDI
Text+ freut sich über die Förderzusage für Jupyter4NFDI, einem durch die beiden an Text+ beteiligten Rechenzentren Jülich und GWDG eingereichten Basisdiensteantrag!
Darüber hinaus werden mit DMP4NFDI und KGI4NFDI zwei weitere Basisdienste in der Initialisierungsphase durch Base4NFDI gefördert.
Events & Nachberichte
Text+ bei der DHd2024
Bei der DHd 2024 vom 26.02.–01.03.2024 in Passau war Text+ an verschiedenen Stellen bei Vorträgen und Postern vertreten. Zum ersten Mal gab es in diesem Jahr einen gemeinsamen Informationsstand mit den NFDI-Konsortien der sog. Memorandum-of-Understanding-Gruppe: NFDI4Culture, NFDI4Memory, NFDI4Objects und natürlich Text+. In der MoU-Gruppe finden Austausch und tlw. eine Zusammenarbeit bei verschiedenen Themen statt.
Text+ Frühjahrstreffen am 12. und 13. März 2024 in Frankfurt am Main
Am 12. und 13. März versammelte sich das NFDI-Konsortium Text+ zu seinem Frühjahrstreffen in der Deutschen Nationalbibliothek (DNB) in Frankfurt am Main. Der erste Tag des Frühjahrstreffens war geprägt von thematischen Arbeitstreffen, die sich auf verschiedene Aspekte konzentrierten. Dazu gehörten beispielsweise Diskussionen zur Weiterentwicklung der Text+ Architektur, insbesondere die Analyse der wesentlichen technischen Komponenten und ihrer Funktionen. Ebenso wurde der aktuelle Stand der Text+ Registry, einem zentralen Baustein des Projekts, der die Auffindbarkeit von Ressourcen verbessert und eine nahtlose Integration mit anderen Infrastrukturen ermöglicht, präsentiert. Des Weiteren wurden die Ingest-Prozesse in den Text+ Datenzentren beleuchtet, mit dem Ziel, sie transparent und benutzerfreundlich zu gestalten, wobei Themen wie Datenformate, Qualitätsbewertung, Lizenzierung und die Zusammenführung von Nutzenden und Datenzentren diskutiert wurden. Am zweiten Tag des Treffens standen die Meetings der Text+ Task Areas im Mittelpunkt, in denen spezifische Arbeitsbereiche vertieft behandelt wurden. Insgesamt war das diesjährige Frühjahrstreffen äußerst produktiv und lieferte wertvolle Impulse für die weitere Entwicklung von Text+.
Nachhaltige Archivierung, Erschließung, Bereitstellung dynamischer Daten aus sozialen Medien – Twitter und danach
Ziel dieser Tagung am 19. und 20. März 2024 in der DNB in Frankfurt am Main war die Vernetzung von Bibliotheken, Archiven, Forschungsinstituten und Forschenden im deutschsprachigen Raum, die sich mit der Archivierung und nachhaltigen Nutzung von Daten und digitalen Objekten aus sozialen Medien beschäftigen. Denn die Archivierung, Erschließung und Bereitstellung dieser dynamischen Daten ist mit Problemstellungen konfrontiert, die all diese Akteuren gleichermaßen betreffen, und für die im besten Fall gemeinsam Lösungsansätze entwickelt werden sollten.
Dass das Thema Querschnittscharakter hat, zeigt nicht nur das große Interesse der Tagungsteilnehmenden – insgesamt hatten sich über 160 Personen angemeldet – sondern auch die Beteiligung zahlreicher NFDI-Konsortien, die im Programmkomitee vertreten waren und die Tagung mitorganisiert haben. Neben Text+ waren das BERD@NFDI, KonsortSWD, NFDI4Culture, NFDI4Data Science und NFDI4Memory.
Das Programm und viele der Präsentationen der Tagung können im öffentlichen DNB-Wiki nachgeschlagen werden.
Codesprint for Humanities Data

Am 11. und 12. April fand an der SUB Göttingen ein Codesprint for Humanities Data statt. Dieser wurde von Measure 5 der Task Area IO zusammen mit der Datendomäne Collections durchgeführt und hatte zum Ziel, den Importworkflow für neue Forschungsdatenbestände ins TextGrid Repository zusammen mit den Teilnehmerinnen und Teilnehmern auszuprobieren. Mit dem neuen Importworkflow – und einigen weiteren neuen Features – ist das TextGrid Repository ein sinnvoller Ort für die Archivierung von textbasierten Forschungsdaten.
Termine
| Datum | Event | Ort |
|---|---|---|
| 25. April 2024 | 9. IO-Lecture: TextGrid Repository | virtuell |
| 30. April 2024 | Text+ Research Rendezvous | virtuell |
| 21. Mai 2024 | Bridging Neurons and Symbols for Natural Language Processing and Knowledge Graphs Reasoning | Turin |
| 29. Mai 2024 | 10. IO-Lecture: Das TextGrid Repository & das Core Trust Seal | virtuell |
| 03. Juni 2024 | Erstes Gemeinsames Meeting aller Coordination Committees von Text+ | virtuell |
| 20. Juni 2024 | 11. IO-Lecture: Die Basisklassifikation in den User Stories von Text+ | virtuell |
| 24. Juni 2024 | Edit-a-thon zur Beschreibung von Ressourcen im SSH Open Marketplace | Bonn |
| 27./28. Juni 2024 | Sprechen verstehen: KI und gesprochene Sprache | München |
| 10./11. Oktober 2024 | 3. Text+ Plenary | Mannheim |