
Herzlich willkommen!
Hier ist der Text+ Newsletter für Dezember 2024. Wir laden Sie herzlich ein, einen Blick in unser Projektgeschehen zu werfen. Über Feedback, Fragen oder Wünsche freuen wir uns. Diese erreichen uns am einfachsten über das Office.
Derzeit verteilen wir den Newsletter alle drei Monate auf verschiedenen Wegen: über die Webseite sowie über unsere E-Mail-Liste an die Community, die über Text+ auf dem Laufenden bleiben möchte. Auf dieser Liste stehen mittlerweile 400 Empfängerinnen und Empfänger. Falls Sie den Newsletter auf diesem Wege erhalten möchten, schreiben Sie uns.
Text+ intern
Sprecherwechsel im NFDI-Konsortium Text+
Zum 1. Oktober 2024 übernahm Prof. Dr. Andreas Witt die Sprecherposition des NFDI-Konsortiums Text+ von Prof. Dr. Erhard Hinrichs. Im Rahmen dieses Wechsels wurde der langjährige Einsatz von Erhard Hinrichs gewürdigt, der maßgeblich zur erfolgreichen Etablierung des Konsortiums beigetragen hat.
Andreas Witt bringt umfangreiche Erfahrung und neue Perspektiven in die Rolle ein, um die zukünftigen Herausforderungen und Chancen von Text+ aktiv zu gestalten. Wir danken Erhard Hinrichs für sein herausragendes Engagement und wünschen Andreas Witt viel Erfolg in seiner neuen Funktion.
Ergebnisse der Wahlen zu den Coordination Committees
Im November 2024 fanden die Wahlen zu den Coordination Committees (CC) von Text+ für die Amtsperiode 2025/2026 statt. Die CCs bestehen aus drei Scientific Coordination Committees, die jeweils eine der Datendomänen – Collections, Editions und Lexical Resources – abdecken, sowie dem Operations Coordination Committee für die Task Area Infrastructure/Operations. Ihre Hauptaufgabe besteht darin, die Entwicklung des Portfolios an Daten, Werkzeugen und Services durch Evaluation und Feedback zu begleiten.
Die CC-Mitglieder werden für eine Amtszeit von zwei Jahren gewählt. Nach einer erfreulich hohen Zahl an Nominierungen startete der Wahlprozess, der sich nach der Verfahrensbeschreibung zur Besetzung der Koordinationskomitees in Text+ richtete. Wahlberechtigt waren Vertretende von Fachverbänden und -verbünden, die Text+ unterstützen, sowie die Institutionen, die Teil des Konsortiums Text+ sind.
Die Wahlbeteiligung lag bei 68,23 %. Nach Abschluss des Wahlverfahrens und Annahme der Wahl durch die Gewählten wurden die Ergebnisse am 4. Dezember 2024 offiziell bekannt gegeben. Die Gewählten werden Anfang 2025 auf den Webseiten des Konsortiums erscheinen.
Wir danken allen Kandidatinnen und Kandidaten für ihre Bereitschaft, sich zur Wahl zu stellen, und gratulieren den Gewählten herzlich. Wir freuen uns auf eine erfolgreiche Zusammenarbeit in der kommenden Amtsperiode.
Danksagung an die Mitglieder der Coordination Committees der Amtsperiode 2023/2024
An dieser Stelle möchten wir uns bei allen CC-Mitgliedern bedanken, die mit dem Ende der aktuellen Amtsperiode aus ihrer Rolle ausscheiden. Ihr Engagement hat die Arbeit von Text+ bereichert und mitgeprägt. Ein besonderer Dank gilt den Vorsitzenden und Stellvertretenden der Komitees, deren Einsatz in den letzten zwei Jahren dazu beigetragen haben, die Ziele des Konsortiums umzusetzen. Ohne sie wäre die Begutachtung der Kooperationsprojekte nicht so qualifiziert möglich gewesen. Wir schätzen Ihre Zeit und Energie außerordentlich und wünschen Ihnen für die Zukunft alles Gute!
Highlights aus dem Blog
In dieser Rubrik stellen wir interessante Beiträge aus dem Text+ Blog vor. Das Blog informiert über Text+ und stellt in Ergänzung zur Webseite auch Work in Progress vor oder erlaubt einen detaillierteren Blick auf individuelle Themen. Alle Beiträge sind mit DOIs versehen und zitierbar.
Beiträge von Gastautorinnen und -autoren zu Themen von Interesse für die Text+ Community sind herzlich willkommen! Schreiben Sie uns, wenn Sie ein Thema haben.
Call for Contributions zum Workshop “Text+: Digitale Forschung auf der Grundlage von Text- und Sprachdaten bereichern” auf der DHd-Konferenz 2025 in Bielefeld
Im Rahmen der Konferenz Digital Humanities im deutschsprachigen Raum (DHd) an der Universität Bielefeld findet am 03. und 04. März 2025 der Workshop “Text+: Digitale Forschung auf der Grundlage von Text- und Sprachdaten bereichern” statt, in dem hands-on ein Blick in das Angebotsportfolio von Text+ geworfen wird und der in Zusammenarbeit mit der Community offene Bedarfe eruiert.
Die Organisator:innen des Workshops ermutigen Teilnehmende, im Vorfeld ihre Bedarfe an Text+ zu adressieren, die über die bestehenden Angebote von Text+ hinausgehen. Dies können neue Tools, Softwarepipelines, Angebote zur Datenablage, Handreichungen, Schulungsangebote u.v.m. sein. Dazu zählen auch Erweiterungen von bestehenden Angeboten um weitere Features und Möglichkeiten.
Erbeten werden Kurzabstracts einer Länge von max. 500 Wörtern, die ein Desideratum im Angebotsportfolio von Text+ darstellen, die dessen Relevanz für die Forschung begründen und Perspektiven aufzeigen, wie der offene Bedarf bedient werden kann.
Fünf Einreichungen erhalten die Möglichkeit, ihren Bedarf im Workshop im Rahmen einer kurzen Präsentation (max. 10 min) zu präsentieren und im Plenum zu diskutieren. Alle Einreichungen sind eingeladen, sich mit einem Poster zu beteiligen, das ihre Bedarfe visuell begründet.
Abstracts werden bis zum 19. Februar 2025, 23:59 Uhr MEZ unter office@text-plus.org entgegengenommen.
Diesen Blogbeitrag zitieren: Text+ Blog-Redaktion (17. Dezember 2024). Call for Contributions zum Workshop “Text+: Digitale Forschung auf der Grundlage von Text- und Sprachdaten bereichern” auf der DHd-Konferenz 2025 in Bielefeld. Text+ Blog. Abgerufen am 20. Dezember 2024 von https://doi.org/10.58079/12y47
Edit empfiehlt #1: Das Große Stammbuch Philipp Hainhofers
Die Sitte, ein Stammbuch, auch “Album Amicorum” oder “Freundschaftsbuch” genannt, zu führen, war um 1600 sehr populär. Das sogenannte Große Stammbuch des Augsburger Kunsthändlers und Agenten Philipp Hainhofer (1578–1647) versammelt Einträge, Widmungen und Wappen hochrangiger Persönlichkeiten aus der Zeit von 1596 bis 1633. Hainhofers Großes Stammbuch zeichnet sich dadurch aus, dass es einst lose und nicht chronologisch, sondern eher nach Personenrang sortierte Einzel- und Doppelblätter aus Pergament und Papier mit Einträgen von Fürst:innen (allein zwei Kaisern!) und Adligen, dazu viele Schmuckblätter enthält. Das Buch diente als Kunstsammlung, Kontaktnachweis und Instrument geschäftlicher wie gesellschaftlicher Praxis. Das kostbare Objekt konnte 2020 für die Herzog August Bibliothek erworben werden. Damit verbunden war ein Forschungsprojekt, um das Stammbuch im Detail zu erschließen und der Öffentlichkeit zugänglich zu machen. Ein Ergebnis dessen ist die kommentierte digitale Edition Philipp Hainhofer · Das Große Stammbuch.
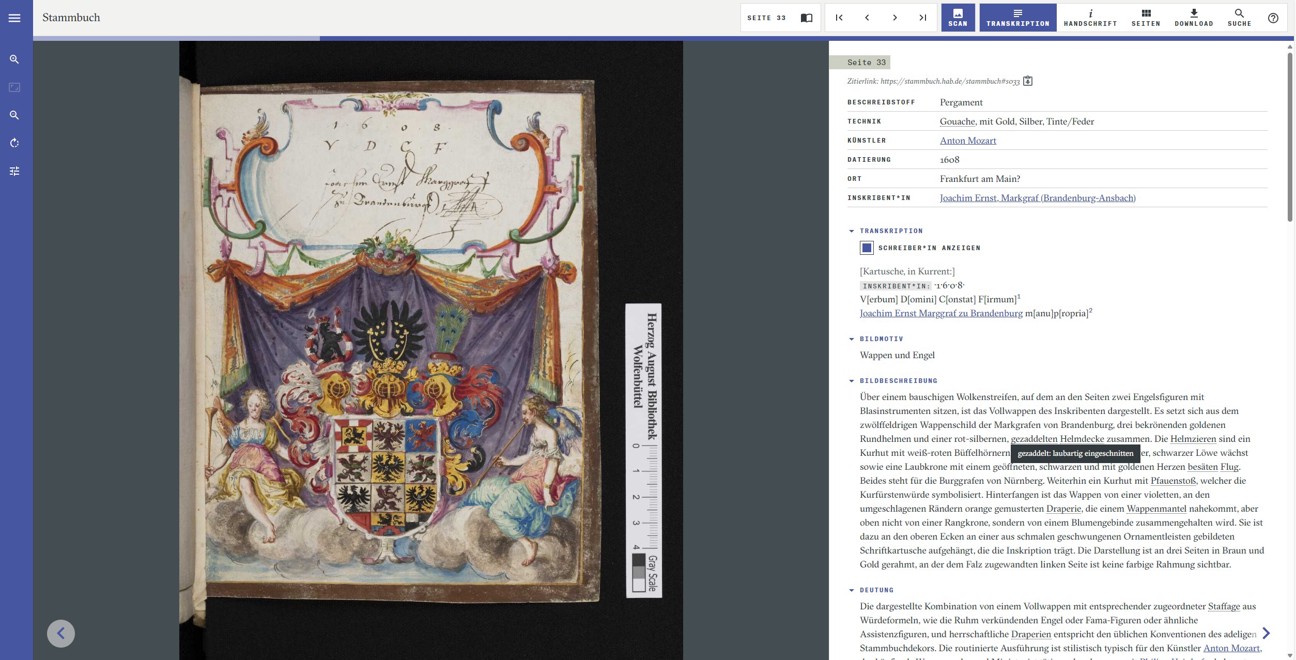
Bitte lesen Sie weiter im Text+ Blog.
Diesen Blogbeitrag zitieren: Kathrin Henseleit, Martin de la Iglesia, Sabine Jagodzinski: Edit empfiehlt #1: Das Große Stammbuch Philipp Hainhofers (Ressourcen-Reigen Spezial). Text+ Blog, 12.11.2024, https://textplus.hypotheses.org/11489.
Werkstattberichte
Core Trust Seal für das TextGrid Repository
Das TextGrid Repository ist ein digitales Langzeitarchiv für geisteswissenschaftliche Forschungsdaten, das einen umfangreichen, durchsuch- und nachnutzbaren Bestand an Texten und Bildern liefert. Es ist an den Grundsätzen von Open Access und den FAIR-Prinzipien orientiert und fokussiert sich auf Texte in XML TEI, um vielfältige Szenarien der Nachnutzung zu unterstützen. Für Forschende bietet das TextGrid Repository eine nachhaltige, dauerhafte und sichere Möglichkeit zur zitierfähigen Publikation ihrer Forschungsdaten und zur verständlichen Beschreibung derselben durch Metadaten. Mehr Informationen zum Thema Nachhaltigkeit, FAIR und Open Access befinden sich im Mission Statement des TextGrid Repository.

Beim CoreTrustSeal (CTS) handelt es sich um eine internationale, gemeinnützige Organisation mit dem Ziel, vertrauenswürdige Dateninfrastrukturen zu fördern. Sie zertifiziert Repositorien auf Grundlage des Anforderungskatalogs der Core Trustworthy Data Repositories Requirements. Dieser fragt Kernkompetenzen von vertrauenswürdigen Repositorien ab. Nachdem eine Zertifizierung beantragt wurde, wird der Antrag von einer Reihe internationaler Prüferinnen und Prüfer bearbeitet. Die CoreTrustSeal-Zertifizierung gehört zu den bekanntesten Zertifizierungen und ist international anerkannt, wie die Liste der zertifizierten Repositorien belegt.
Der Anforderungskatalog gliedert sich in 16 verschiedene Kriterien und enthält Fragen zur Organisation, die hinter dem Repositorium steht, zum digitalen Objektmanagement sowie zu Technik und Sicherheit. Dazu gehören beispielsweise ein Mission Statement, rechtliche und ethische Aspekte, die Dokumentation von Workflows, Metadatenstandards und technische Infrastruktur. Nur wenn alle Kriterien erfüllt sind, darf ein Repositorium das CoreTrustSeal-Zertifikat führen. Bei der Zertifizierung des TextGrid Repositorys hat sich besonders seine ausführliche allgemeine Dokumentation sowie die API-Dokumentation bewährt. Gleichzeitig wurde positiv hervorgehoben, dass die Qualität der Metadaten und die Umsetzung von Bedürfnissen der designierten Community bei der Gestaltung des TextGrid Repositorys so eine wichtige Rolle spielen.
Weitere inhaltliche Informationen zum TextGrid Repository finden Sie im Dokumentationsbereich der TextGrid-Website, technische Informationen auf der Dokumentationsseite des Repository-Servers.
Anwendungsbeispiele
Für FAIRe Forschungsdaten ist die Orientierung an etablierten und weit verbreiteten Standards für Objekt- und Metadaten essentiell. Insbesondere zur Gewährleistung von Auffindbarkeit, Interoperabilität und Nachnutzbarkeit in einer ortsverteilten Infrastruktur wie der in Text+ sind einheitliche Formate und Standards über die Repositorien hinweg unerlässlich. In einem eigenen Bereich des Portals stellt Text+ Informationen, Angebote und Anschauungsmaterial rund um die Standardisierung von Forschungsdaten zur Verfügung.
Neu hinzugekommen sind nun Anwendungsbeispiele aus der Praxis der Datendomänen und der Kooperationsprojekte. In den vorgestellten Vorhaben aus den Text- und Sprachwissenschaften werden von Text+ empfohlene Standards und standardbasierte Tools erfolgreich eingesetzt:
- correspSearch - Briefeditionen durchsuchen und vernetzen
- Das Deutsche Referenzkorpus (DeReKo)
- Deutsche Textarchiv (DTA)
- edition humboldt digital
- Klaus Mollenhauer Gesamtausgabe (KMG)
- Text+ Kooperationsprojekt INSERT
Rund um die Anwendungsbeispiele wird in 2025 auch eine Werkstattreihe angeboten, in der Vorhaben vorgestellt und diskutiert werden können. Die Anmeldung zur ersten Veranstaltung am 20. März: DTABf - Das Deutsche Textarchiv-Basisformat ist bereits möglich.
Publikationen, Services & Infoangebote
Text+ pflegt seine Bibliographie bei Zotero und stellt auf seinem Portal eine strukturierte Ansicht dar.
Die interoperable Edition ‚sub specie durationis‘
Wir möchten Ihnen einen Artikel aus der Zeitschrift editio vorstellen
- Hegel, Philipp, Tessa Gengnagel, Kilian Hensen, Karoline Lemke, and Gerrit Brüning. “Die interoperable Edition ‚sub specie durationis‘.” editio 38, no. 1 (November 1, 2024): 135–46. https://doi.org/10.1515/editio-2024-0008.
Der Beitrag untersucht die Rolle spezifischer Datenformate als Vermittler zwischen projektspezifischen Datenmodellen und vernetzten digitalen Ressourcen. Besonders hervorgehoben werden das Potenzial von Pivot-Formaten sowie das BEACON-Format. Durch die nähere Betrachtung verschiedener Formate und Softwaretools zur Datenaufbereitung, -transformation und -analyse wird aufgezeigt, dass zusätzliche maschinenlesbare Formate die Langlebigkeit und Interoperabilität digitaler Editionen verbessern können.
Events & Nachberichte
Webinar zu den rechtlichen Aspekten der Erhebung und Weitergabe von Social-Media-Daten
Am 25. November organisierte CLARIN-CH (das Schweizer CLARIN-Konsortium) ein Webinar zu den rechtlichen Aspekten der Erhebung und Weitergabe von Social-Media-Daten. Dr. iur. Paweł Kamocki, Rechtsexperte am Leibniz-Institut für Deutsche Sprache in Mannheim und Co-Vorsitzender der Text+-AG Legal, hielt einen eingeladenen Vortrag. In seiner Präsentation beleuchtete er die rechtlichen Herausforderungen bei der Nutzung von Social-Media-Daten für sprachwissenschaftliche Zwecke. Zu den zentralen Themen gehörten Urheberrechte, Ausnahmen für Text- und Datamining (TDM), die Bedeutung von Nutzungsbedingungen, Datenschutzgesetze sowie das neue regulatorische Rahmenwerk im Rahmen des Digital Services Act.
Die Präsentationsfolien und die Aufzeichnung des Vortrags sind unter folgendem Link verfügbar: https://clarin-ch.ch/news/2024/10/22_1729589265.
Bericht vom 5. FID/Text+ Jour Fixe: “Verzeichnen und Ablegen (and beyond)” am 27. November 2024 im Präsenz an der SUB Göttingen
Fachinformationsdienste und NFDI haben teilweise vergleichbare Ziele. Aus diesem Grund trafen sich Text+ und mit Text+ assoziierte Fachinformationsdienste am 27. November bereits zum fünften Mal zum regelmäßigen FID/Text+ Jour fixe, diesmal in Präsenz an der Niedersächsischen Staats- und Universitätsbibliothek Göttingen (https://events.gwdg.de/event/960/).
Drei große Themen standen im Fokus: Die Text+ Registry und deren Gestaltung, zu der Fachinformationsdienste wertvollen Input aus ihren Communitys liefern konnten; das Data Depositing als Thema aller von den Anwesenden vertretenen Communitys sowie beispielhaft die Depositing-Angebote der Datenzentren von Text+; die Zielsetzung des JF, der nun erstmalig von FIDen und Text+ gemeinsam organisiert und thematisch bespielt wurde. Daneben gab es ausreichend Zeit für weitere Themen (z. B. die gemeinsame Übersetzung der Basisklassifikation oder den stärkeren gegenseitigen Support bei der Einwerbung von Fördermitteln) und Diskussionen. So konnte der JF einen weiteren Beitrag zur tieferen Verschränkung beider Strukturen leisten und man war sich einig, ihn in regelmäßigen Abständen fortzusetzen.
Dank gilt insbesondere den für die Organisation Verantwortlichen aus FIDen und der Text+ AG FID Koop sowie der SUB Göttingen als Gastgeberin. Ein Blogpost zur ausführlichen Nachlese befindet sich in Vorbereitung.
Entity Linking, eine Text+ IO-Lecture
Am 18. September 2024 fand die bereits 16. Text+ IO-Lecture statt – diesmal zum Thema Entity Linking. Die Text+ IO-Lectures sind offen für alle Interessierten und greifen infrastrukturbezogene Themen auf. IO tritt in Text+ in einer Providerrolle auf und ermittelt zusammen mit den anderen Task Areas wissenschaftliche Bedarfe für Angebote von Text+. Daraus ergibt sich ein Bedarf an Information und Beratung, den IO durch die regelmäßige, niedrigschwellige Reihe der IO-Lectures bedient. Zusätzlich decken die IO-Lectures Themen ab, die über Text+ hinaus in der NFDI und für Forschungsinfrastrukturen im Allgemeinen von Interesse sind.
Nach einer kurzen Einführung des Themas durch Felix Helfer (SAW), wurde zunächst von Alexander Bartmuß (SAW) ein im Aufbau befindlicher Datensatz vorgestellt, für den auch Entity Linking eine zentrale Rolle spielt: die “Briefe und Akten zur Kirchenpolitik Friedrichs des Weisen und Johanns des Beständigen 1513 bis 1532” aus dem gleichnamigen Projekt der SAW. Den Teilnehmer:innen der Lecture wurde ein Einblick in das Projekt und insbesondere die Arbeitsschritte, Vorteile und Herausforderungen der manuellen Verlinkung der dort auftretenden Entitäten gegeben. Denn so nützlich die Anreicherung von textbasierten Daten auf diese Weise ist, so aufwändig ist die tatsächliche Umsetzung des konkreten Vorhabens.
Ist eine manuelle Bearbeitung nicht umsetzbar, könnten Verfahren des automatischen Entity Linkings weiterhelfen. Doch wie verlässlich sind bestehende Lösungsansätze, insbesondere für deutsche Forschungsdaten? Hierzu hat Pia Schwarz (IDS) ihr Benchmark vorgestellt, welches die Performanz existierender Werkzeuge untersucht. Das Fazit des Benchmarks: Qualität in allen Fällen definitiv ausbaufähig!
Außerdem wurde eine in Arbeit befindliche Untersuchung eines LLM-basierten Ansatzes via Prompting gezeigt, um zukünftig vielleicht bessere Möglichkeiten zur Verfügung zu haben. Dabei werden zunächst verschiedene Kandidaten inklusive Beschreibung für eine Enität aus einer Wissensbasis extrahiert und anschließend ein LLM für die Disambiguierung gepromptet. Erste Experimente haben gezeigt, dass die Ergebnisse besser sind als die Modelle, die zuvor evaluiert wurden.
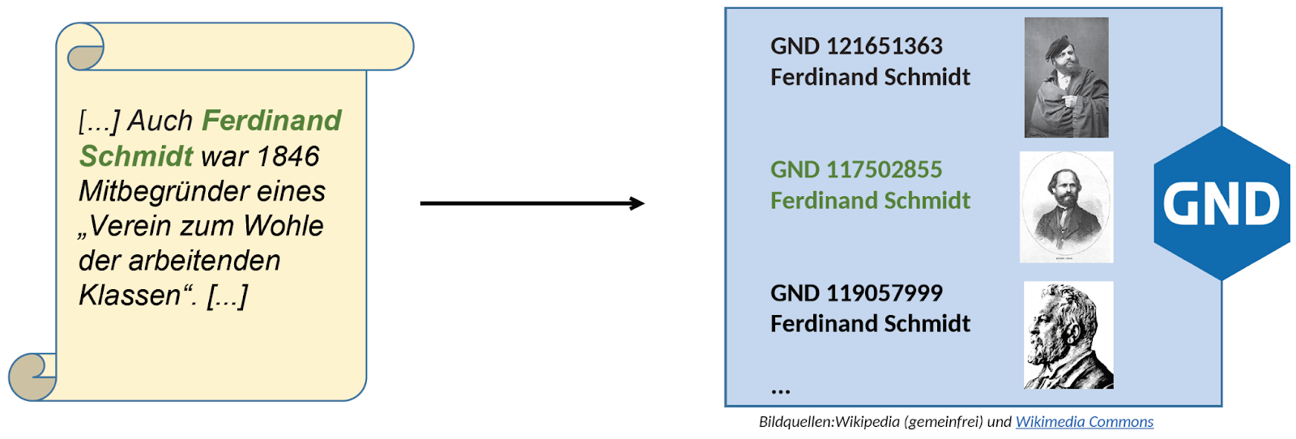
Mit dieser Hoffnung begann auch der zweite Teil der Lecture, der sich vor allem um laufende Arbeiten in Text+ zum Thema Entity Linking drehte. Zunächst wurden Experimente mit sogenannten “Entity-Embeddings” auf Daten des Wortschatz Leipzig vorgestellt. Hierfür werden für GND-Entitäten Embeddings aus Kontextdaten (genauer: Wikipedia-Artikel zu den jeweiligen Entitäten) erzeugt, welche dann über gängige Ähnlichkeitsmetriken mit Embeddings von Entitäten aus einem Eingabetext und deren Kontext verglichen werden können.
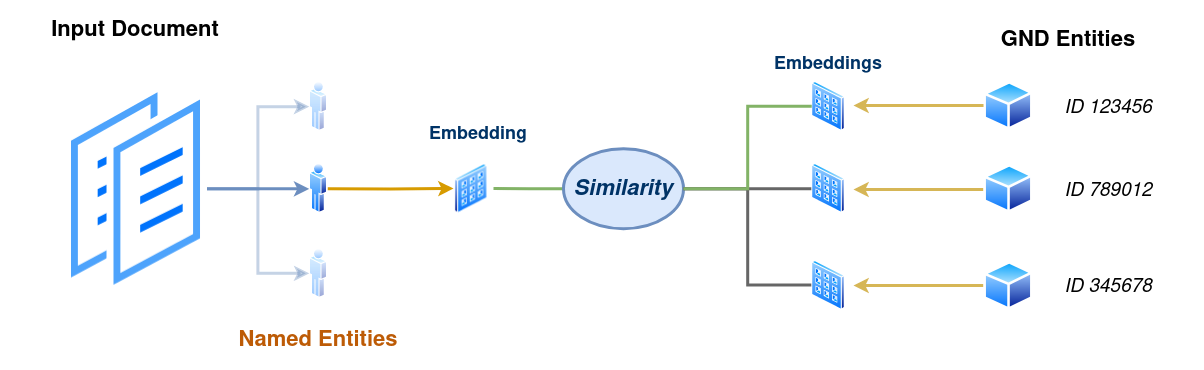
Diesem niederschwelligen Ansatz folgend präsentierte Jonas Richter (Universität Leipzig) seine Abschlussarbeit, in der eine fortschrittlichere Herangehensweise erprobt werden soll: ein neuronales Modell, welches Entitäten anhand von in der GND enthaltenen Informationen (wie Orts- und Zeitangaben) verlinkt. Zusätzlich soll die Kandidatensuche, ein wichtiger Teilschritt der Gesamtaufgabe welcher den initial sehr weiten Suchraum verkleinern soll, gegenüber einer einfachen Stringsuche verbessert werden – auch hier sollen Embedding-Ähnlichkeiten helfen, zielsicherer passende Kandidaten in der Wissensbasis zu ermitteln.
Aber nicht nur die Erzeugung neuer Datensätze war Thema dieser Werkschau, auch die Anwendung bereits annotierter Datensätze sollte nicht zu kurz kommen. So wurde die Lecture mit einem Einblick in eine Erweiterung der Föderierte Inhaltssuche (FCS) abgeschlossen, welche an der SAW entwickelt wird.
Die FCS ist, das verrät bereits ihr Name, eine Spezifikation und Plattform zur inhaltlichen Suche in verteilten (föderierten) Ressourcen. Viele Datenbestände in Text+ sind bereits über die projekteigene FCS durchsuchbar. Sie wird jedoch auch beständig erweitert, so eben um eine entitätenbasierte Inhaltssuche, um etwa eine Entität anhand ihrer GND-ID in einem entsprechend annotierten Datensatz finden zu können. Und so endete diese Lecture auch mit der Vorführung des bereits lauffähigen Prototypen dieser EntityFCS – mit Daten aus den anfangs gezeigten Briefen und Akten zur Kirchenpolitik!
Dass das Thema viele Forschende interessiert und konkrete Praxisrelevanz aufweist, zeigte sich nicht nur an der Anzahl der Teilnehmer:innen, sondern auch an den regen Frage- und Diskussionsrunden zwischen den Beiträgen. Entity Linking wird in Text+, so lässt es sich nach dieser Lecture vermuten, weiterhin im Gespräch bleiben!
Felix Helfer (31. Oktober 2024). Entity Linking, eine Text+ IO-Lecture. Text+ Blog. Abgerufen am 20. Dezember 2024 von https://doi.org/10.58079/12lp4
GND Forum NFDI, FIDs & co. am 10. Dezember 2024
Einmal quer Beet - Projektübergreifende Eindrücke zu Arbeiten rund um die GND
Auch wenn sich noch weitaus mehr Menschen für das GND Forum NFDI, FID & Co am 10. Dezember 2024 angemeldet hatten, so waren wir von den tatsächlich teilnehmenden 250 Menschen wirklich sehr angetan. Für die Teilnehmenden hatte das Team der Niedersächsischen Staats- und Universitätsbibliothek Göttingen und der Arbeitsstelle für Standardisierung der Deutschen Nationalbibliothek aus den Communities der geisteswissenschaftlichen Konsortien der Nationalen Forschungsdateninfrastruktur (NFDI), den Fachinformationsdiensten der Wissenschaften und weiteren Forschungsvorhaben einen Strauß an Vorträgen zu einem dichten Programm zusammengestellt.
Das GND Forum NFDI, FID & Co lud so alle Interessierten ein, sich über aktuelle Vorhaben zur Gemeinsamen Normdatei (GND) im deutschsprachigen Raum zu informieren. Da es sich im Wesentlichen um eine Informationsveranstaltung handelte, liegt der Schwerpunkt der Dokumentation auf der Bereitstellung der Folien zu den neun Vorträgen. Die Vorträge behandelten die unterschiedlichen Aspekte der Arbeit mit der GND aus verschiedenen Perspektiven und stellten die Rolle der GND für die unterschiedlichen Communities vor. Die meisten Vorträge kann man gut mit der Kategorie ”Werkstattbericht” beschreiben. Sie waren so heterogen in Inhalt und vorausgesetztem Wissen, wie das Publikum selbst. Der neunte Vortrag rundete das Programm mit einer Präsentation einer Pilotanwendung für eine KI-gestützte Inhaltserschließung ab. Untenstehend das vollständige Programm.

Termine
Alle Veranstaltungen - sowohl kommende als auch bereits stattgefundene - finden Sie auch in unserer Veranstaltungsrolle im Text+ Portal..
Gemeinsamer Workshop über Large Language Models (LLMs) im Publizieren
Wie werden Large Language Models (LLMs) die Zukunft des wissenschaftlichen Publizierens verändern? Um diese zentrale Frage zu diskutieren, organisieren sechs NFDI-Konsortien am 11. Februar 2025 einen eintägigen Workshop zum Thema „Large Language Models and the Future of Scientific Publishing“. Die transdisziplinäre Veranstaltung bringt Vertreter aus dem Wissenschaftsbetrieb, aus dem Verlagswesen und Tool-Entwickler zusammen, um die Chancen und Herausforderungen zu diskutieren, die der Einsatz von LLMs mit sich bringt. Die Teilnahme ist kostenlos, Anmeldung und weitere Informationen unter: https://indico3-jsc.fz-juelich.de/event/202/
| Datum | Event | Ort |
|---|---|---|
| 09. Januar 2025 | Text+ Research Rendezvous | virtuell |
| 5. Februar 2025 | FAIR February 2025: F wie Qualitätssicherung | virtuell |
| 10. Februar 2025 | Text+ IO-Lecture: OAPEN & DOAB | virtuell |
| 11. Februar 2025 | Large Language Models and the future of scientific publishing | virtuell |
| 12. Februar 2025 | FAIR February 2025: A wie User Experience | virtuell |
| 19. Februar 2025 | FAIR February 2025: I wie BEACON | virtuell |
| 26. Februar 2025 | FAIR February 2025: R wie Dokumentation | virtuell |