Dienste und Werkzeuge
Text+ und die beteiligten Einrichtungen stellen eine Vielzahl von Angeboten rund um Sprach- und Textdaten zur Verfügung. Neben den Forschungsdaten sind Dienste und Werkzeuge ein wesentlicher Teil des Text+ Angebots für die Nutzenden.
Für die Bereitstellung und Pflege dieser Dienste und Werkzeuge nutzt Text+ den SSH Open Marketplace, eine Discovery-Plattform aus dem Social Sciences and Humanities Cluster in der EOSC. Die dargestellte Angebotsliste kann nach verschiedenen Bedarfen gefiltert werden und unterliegt ständiger Weiterentwicklung. Feedback und Wünsche können an den Helpdesk mit dem Betreff Infrastruktur/Betrieb gerichtet werden.
Activities
Keywords
Atlas zur Aussprache des deutschen Gebrauchsstandards (AADG)
Der Atlas zur Aussprache des deutschen Gebrauchsstandards (AADG) dokumentiert die regionale Variation des deutschen Gebrauchsstandards anhand kommentierter Sprachkarten zu ausgewählten Phänomenen, besonders aus dem Bereich der Aussprache.

BAS CLARIN Repository
Repository of 50+ annotated speech corpora. Most corpora may be accessed and downloaded by members of academic research institutions, some corpora require licenses, e.g. highly sensitive data, or data for commercial use.


CLARIAH-DE Tutorial Finder
The Tutorial Finder allows users to browse freely available and reusable teaching and training materials on procedures, tools, research methods, and topics in the humanities and its related disciplines.
This resource is supported by Text+.

CLARIND-UdS
CLARIND-UdS is a repository for language resources at Saarland University.
CLARIND-UdS FCS Endpoint (Saarbrücken)
The CLARIND-UdS data center is part of the Text+ infrastructure and operated by the Department of Language Science and Technology at Saarland University.

CLARIND-UdS Repository (Saarbrücken)
The CLARIND-UdS data center is part of the Text+ infrastructure and operated by the Department of Language Science and Technology at Saarland University.
CMDI Explorer
CMDI Explorer is a tool that empowers users to easily explore the contents of complex CMDI records and to process selected parts of them with little effort.
Corpus Services
The (HZSK) Corpus Services were initially developed at the Hamburg Centre for Language Corpora (HZSK) as a quality control and publication framework for EXMARaLDA corpora. Since then, most development work has been done within the INEL project.
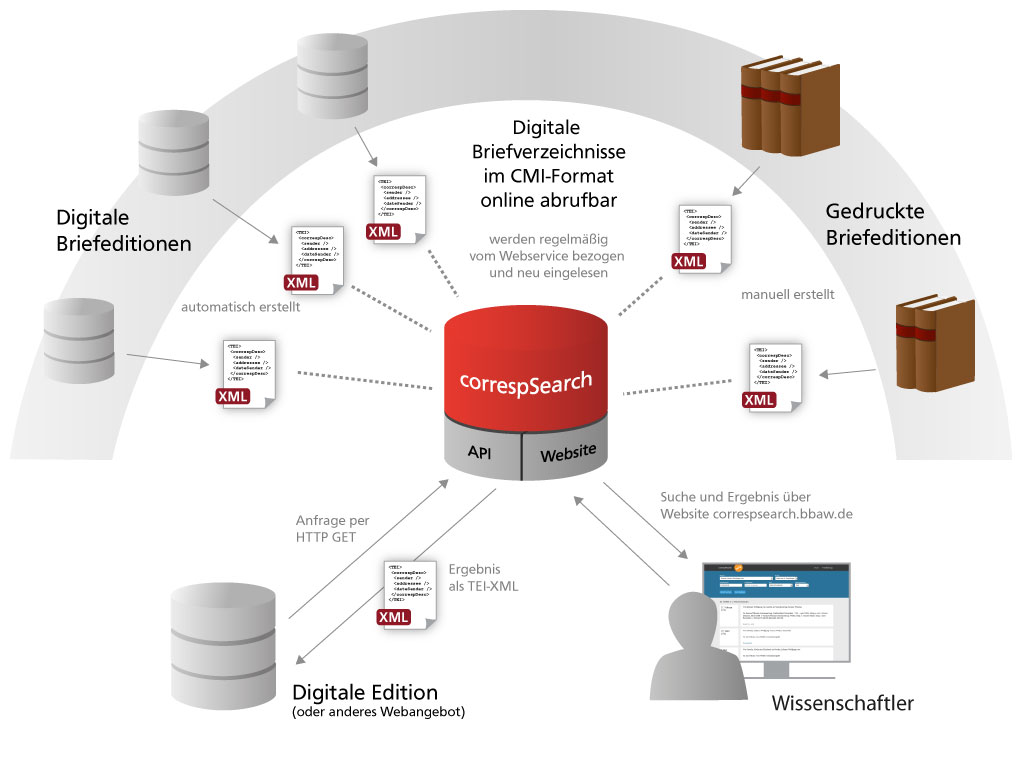
correspSearch - Search and Connect Scholarly Editions of Correspondence
With correspSearch you can search within the metadata of diverse edited letters from different scholarly editions and other scholarly publications. One can search according to the letter's sender, adressee, as well as place and date of the letter's creation.

Critical Pāli Dictionary Online
The Critical Pāli Dictionary Online (CPD) is a digital version of the "Critical Pāli Dictionary", which is a comprehensive dictionary of the Pāli language.
DARIAH-CAMPUS
Looking for learning resources?
DARIAH-DE and OPERAS-GER academic blogging with Hypotheses
Hypotheses is a non-commercial blog portal for the humanities and social sciences. The portal provides a free service that facilitates scientific blogging and ensures greater visibility as well as archiving of content.
DARIAH-DE Data Federation Architecture (DFA)
The DARIAH-DE data federation architecture is the term for services and tools that enable research data and collection descriptions to be found from various sources (such as cultural institutions, libraries, archives, research facilities, and data centers) and to be used for analysis.
DARIAH-DE Data Modeling Environment
Environment for modeling data and their relationships.
The Data Modeling Environment (DME) is a tool for modeling and associating data. By means of the DME, data models and mappings between them are defined and provided in terms of interfaces (REST-API).
DARIAH-DE Generic Search
Search engine that allows to search in the metadata records of the Collection Registry
The Generic Search creates a comprehensive search facility in DARIAH-DE.
DARIAH-DE Geo-Browser
The DARIAH-DE Geo-Browser (or GeoBrowser) allows a comparative visualisation of several requests and facilitates the representation of data and their visualisation in a correlation of geographic spatial relations at corresponding points of time and sequences.

DARIAH-DE Helpdesk (DARIAH-EU, Text+)
A good starting point to receive support for DH-related questions, tools and resources provided by CLARIN-D, DARIAH-EU and DARIAH-DE, and Text+ is the helpdesk. Its aim is to answer to each request within 24 hours and either solve the issue directly or channel the issue to competent colleagues.
DARIAH-DE Monitoring of research infrastructures and services using Icinga
Monitoring is a important factor for the operation of a digital research infrastructure. The data centers focus the hardware and the state of the basic software. Monitoring can be used to correct any faults and failures as quickly as possible.
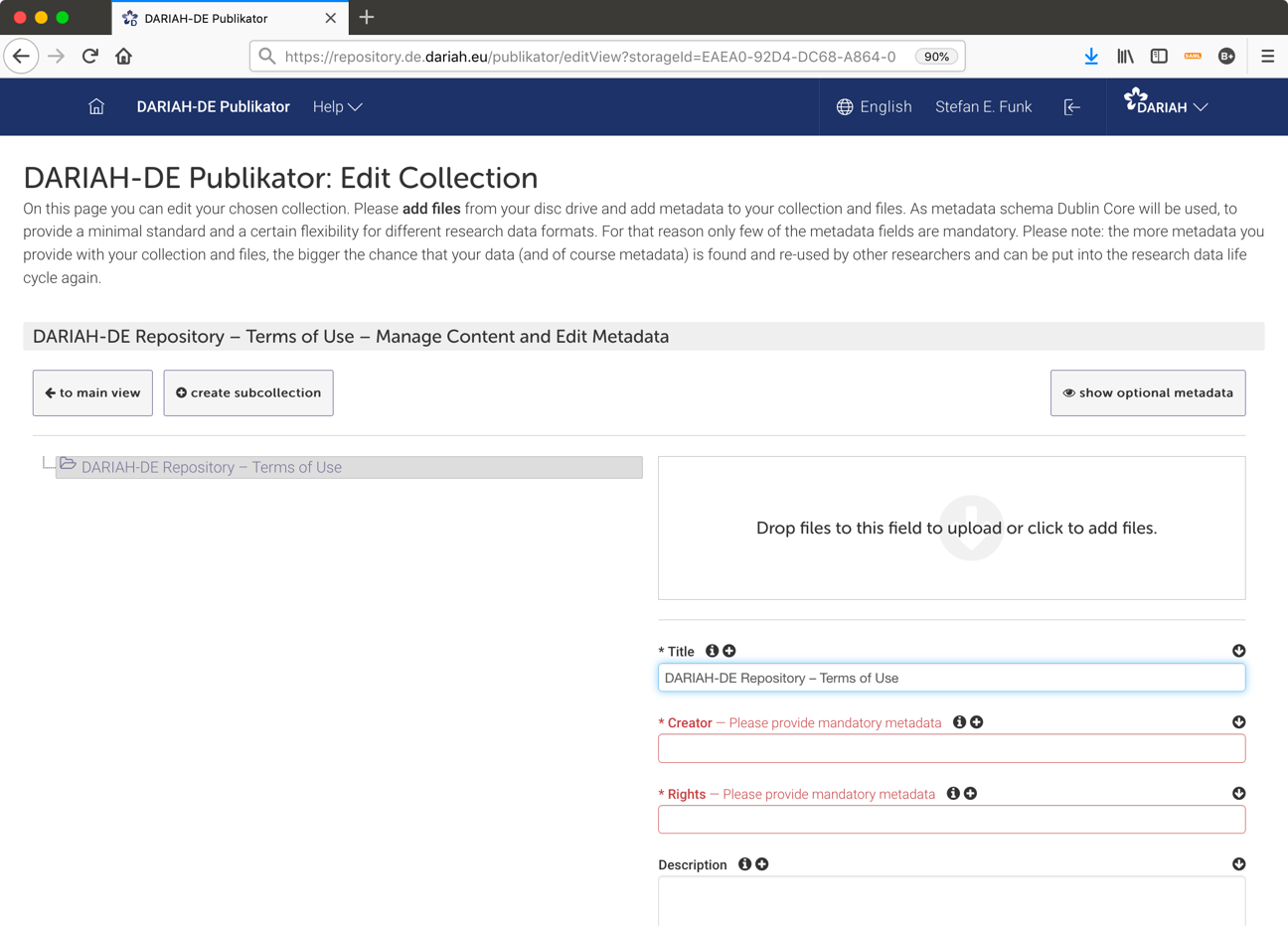
DARIAH-DE Publikator
For whom? Researchers who want to deposit their research data safe, persistent, and referencable in a research data repository.
The DARIAH-DE Publikator offers the possibility to prepare, manage and import research data for the import into the DARIAH-DE Repository.

DARIAH-DE Repository dhrep
The DARIAH-DE Repository is a central component of the DARIAH-DE research data federation architecture. The DFA aggregates various services and, thus, ensures a convenient use.
Datenbank für Gesprochenes Deutsch (DGD)
Die Datenbank für Gesprochenes Deutsch (DGD) am IDS ist ein webbasiertes Korpusmanagementsystem für gesprochene Sprache, das speziell für Forschung und Lehre entwickelt wurde.
DeReKo – Korpus-Downloads
Der weitaus größte Teil von DeReKo kann für nicht-kommerzielle Zwecke kostenlos über COSMAS II genutzt werden. Für wissenschaftliche Zwecke stellt das IDS nach Unterzeichnung einer Lizenzvereinbarung ausgewählte Korpora der geschriebenen Sprache kostenlos zur Verfügung.
DeReKoVecs
DeReKoVecs ist ein Forschungs‑Tool des IDS, das die Analyse und den Vergleich von Methoden zur Untersuchung paradigmatischer und syntagmatischer Wortbeziehungen ermöglicht.
DeReWo
DeReWo ist ein korpusbasiertes Forschungs‑Tool des IDS zur Erstellung von häufigkeitsbasierten Grund- und Wortformenlisten.
Deutsches Textarchiv (DTA)
The German Text Archive is a Repository for historical, German-language text corpora at Zentrum Sprache of the Berlin-Brandenburg Academy of Sciences and Humanities.
Digital Collection of Germany National Library
Our digital collections consist of e-books, e-papers and e-journals, online dissertations, audio books, digitally recorded music, websites and digitised works.
Digital Humanities Call
Digital Humanities Call (starting every year in March): We will gladly support you with your research project by providing metadata, digital objects and infrastructures. The provisions in section 60d UrhG apply.
Digitales Wörterbuch der deutschen Sprache (DWDS)
The Digital Dictionary of the German Language (DWDS) is a lexical system at the Berlin-Brandenburg Academy of Sciences and Humanities that provides information about German vocabulary in the past and present.

DNBLab
The German National Library offers free access to its bibliographic data and several collections of digital objects. As the central access point for presenting, accessing and reusing digital resources, DNBLab allows users to access our data, object files and full texts.
DTA Base Format (DTABf)
Format standard for TEI-compliant text annotation of digital full texts of historical prints with an extension for manuscripts.
DTA FCS-Endpoint
Endpoint for the Text+ Federated Content Search to query DTAXL, the historical corpora of the DTA at BBAW.
DWDS FCS-Endpoint
Endpoint for the Text+ Federated Content Search to query DWDSXL, a collection of contemporary text corpora at BBAW.
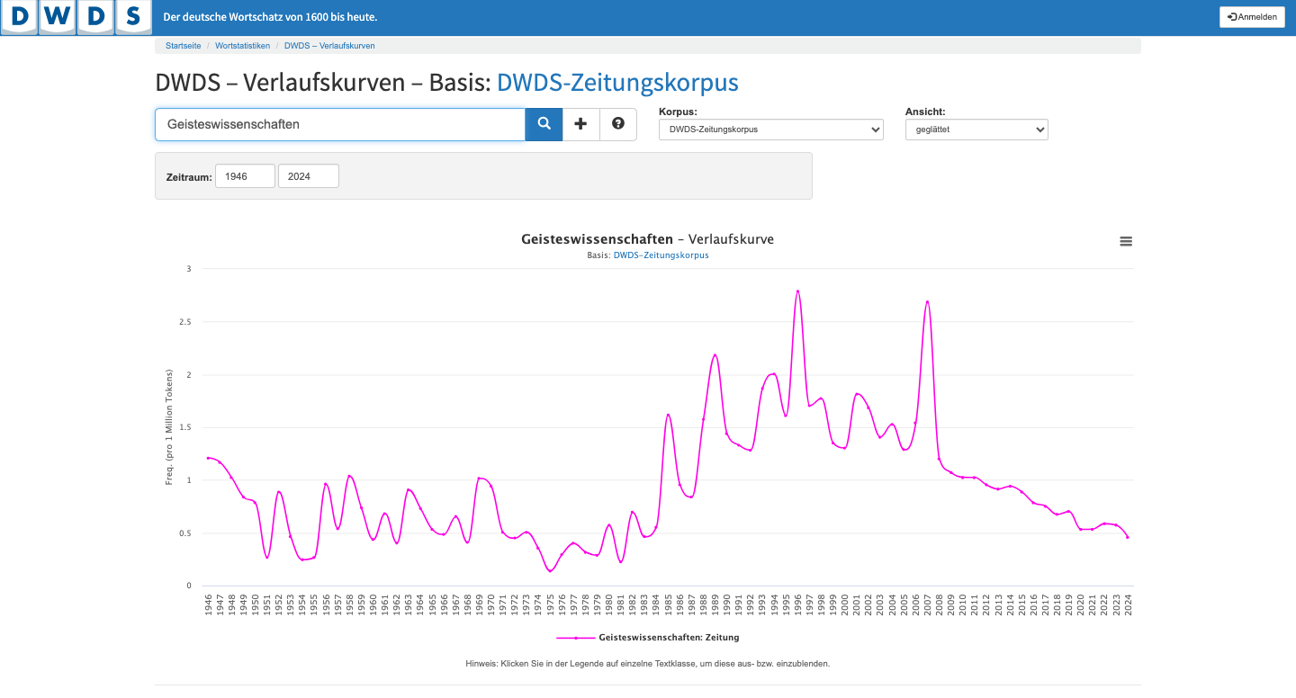
DWDS word history curve
Tool of the Digital Dictionary of the German Language (DWDS) at the Berlin-Brandenburg Academy of Sciences and Humanities (BBAW) for the diachronic analysis of word usages.
DWDS-API
An application programming interface (API) for querying DWDS-corpora at Berlin-Brandenburg Academy of Sciences and Humanities (BBAW). It's the API interface of the Digital Dictionary of the German Language (DWDS).
ediarum
With ediarum researchers can comfortably transcribe, encode and edit manuscripts in TEI-XML, as well as publish their results in an online or print edition. The solution, developed by TELOTA, is based on three software components: exist-db, Oxygen XML Author, and ConTeXt.
EmuR
The main R package for the EMU Speech Database Management System (EMU-SDMS). R package to integrate signal processing, customized graphical output and interactive phonetic segmentation into the R statistics package.
entityXML
entityXML is (so far) a concept study in version 0.6.5 (BETA), which aims to model a standardised XML-based data format for the GND Agency Text+.
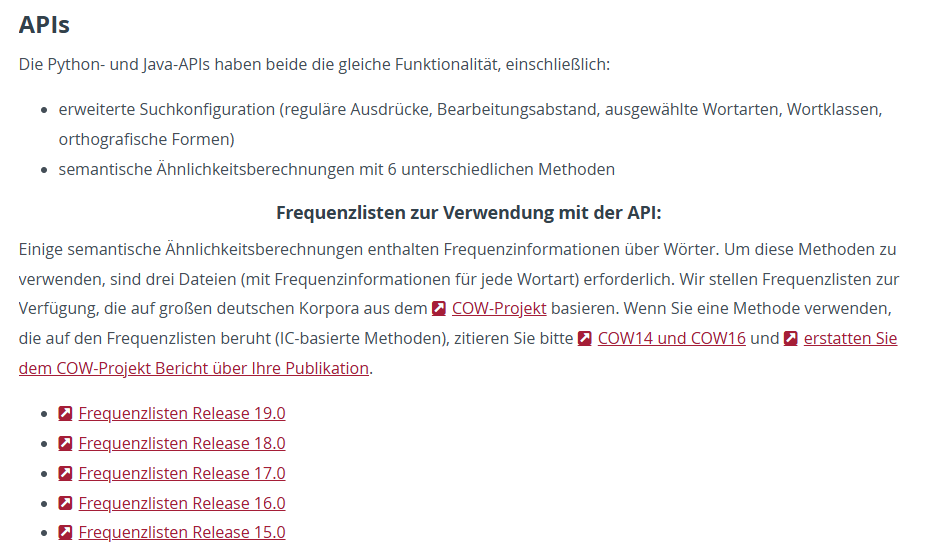
GermaNet API
GermaNet kann über eine API in jeweils Python- und Java angesprochen werden.
GermaNet FCS Endpoint
Der GermaNet FCS Endpunkt liefert GermaNet-basierte Resultate auf die FCS query language.
GermaNet Rover
Rover ist eine Online-Anwendung, die zur Nutzung der GermaNet-Daten oder zur Berechnung der semantischen Verwandtschaft/Ähnlichkeit zwischen zwei Synsets verwendet werden kann.

GND Agency Text+
The GND Agency Text+ is a service that is being set up at the Göttingen State and University Library (SUB Göttingen) as part of the NFDI consortium Text+.

GND-Explorer
Informative, visual, interconnected: The GND Explorer will be the new tool for presenting and searching the Integrated German authority file (GND)! In the future, the GND explorer should provide a convenient and comprehensive access to the GND and its semantic network for all users.
Grammatisches Informationssystem grammis
Grammis ist ein wissenschaftliches Informationssystem zur deutschen Grammatik.
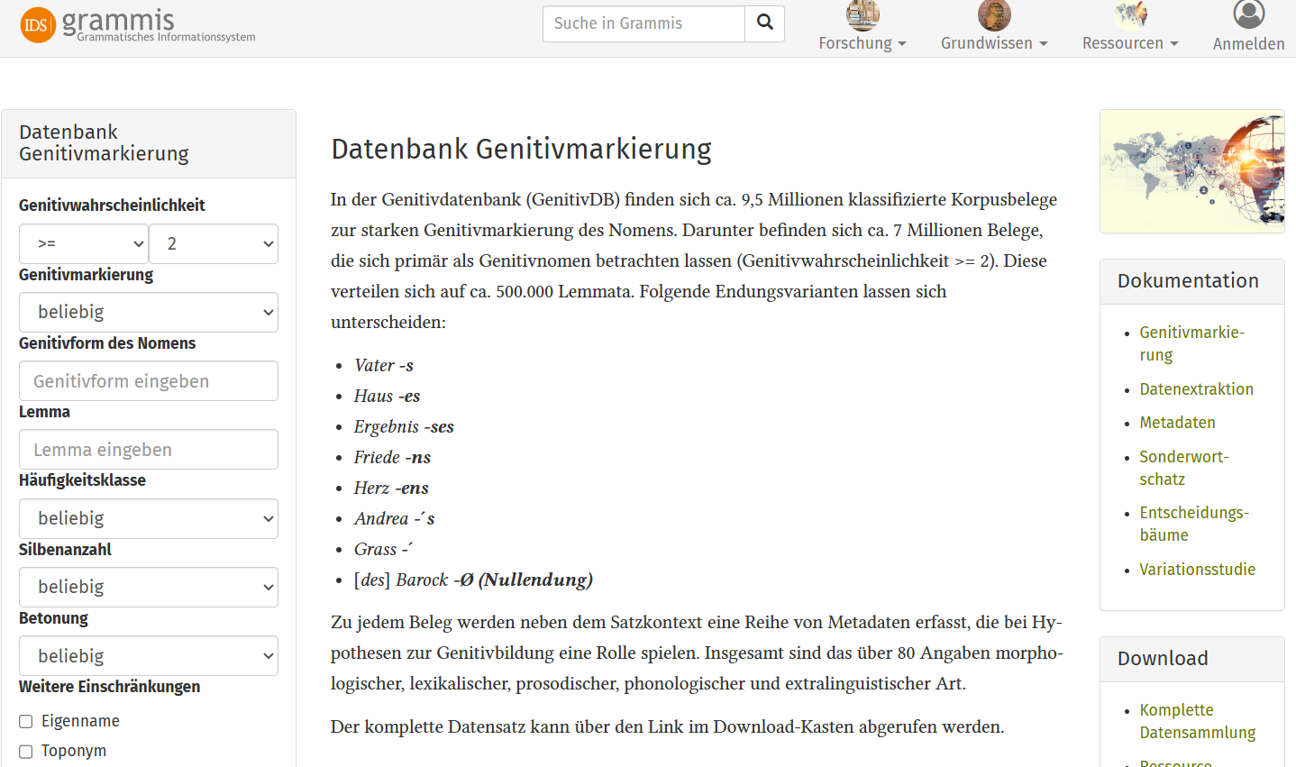
grammis - Korpusgrammatik
Korpusgestützte Erforschung von Variation im standardsprachlichen und standardnahen Deutsch.
grammis - Systematische Grammatik
Systematische Grammatik bietet eine wissenschaftlich fundierte Beschreibung der deutschen Grammatik aus syntaktischer, semantischer und kommunikativ-funktionaler Perspektive.
grammis - Valenzwörterbuch
Das Wörterbuch zur Verbvalenz enthält grammatisch relevante Informationen zu knapp 700 ausgewählten deutschen Verben.
HedgeDoc - GWDG Pad
Online tool for collaborative text editing to work together on the same texts at the same time.
The HedgeDoc-pad is an open-source-based web editor that allows multiple users to work on a single text simultaneously from different locations.
IDS Repository
Das IDS-Repositorium übernimmt die Langzeitarchivierung linguistischer und sprachlicher Ressourcen im Bereich der Germanistik und fungiert als Schnittstelle zum Virtual Language Observatory, von wo aus die Daten über eine Facettensuche exploriert werden können.
Indico Event Management
The open source software Indico developed by Cern is a web application. Lectures, meetings and conferences can be created using Indico. Three different event types (lecture, meeting and conference) can be created in Indico.
Integrated Authority File (GND)
The Integrated Authority File (GND) is a service facilitating the collaborative use and administration of authority data. These authority data represent and describe entities, i.e.
KoGra-R - Statistische Verfahren für korpusbasierte Häufigkeiten
KoGra-R ist ein digitales Analyse-Tool des IDS für die statistische Auswertung und Visualisierung der Ergebnisse von Sprachkorpusrecherchen. Es ermöglicht das Laden und Auswerten von COSMAS-Frequenzlisten sowie frei erstellten Tabellen.

KorAP
KorAP ist eine moderne Korpusanalyse-Plattform des IDS, optimiert für sehr große, mehrfach annotierte Korpora.
KorAP (on DeReKo)
This is a corpus analysis platform that is suited for large, multiply annotated corpora and complex search queries independent of particular research questions.
Language Archive Cologne (LAC)
The Language Archive Cologne (LAC) supports research, learning and teaching with high quality and dependable digital language resources. The LAC facilitates free and open online access to research data.

Language Resource Switchboard
A web application that suggests language analysis tools for specific data sets.

Lehnwortportal Deutsch
Durch vielfältigen Sprachkontakt hat das Deutsche im Wortschatz zahlreicher Sprachen Spuren hinterlassen.
MeineDGS - ANNIS
ANNIS Instances of the Public German Sign Language Corpus, created by at Institute of German Sign Language and Communication of the Deaf in the framework of the longterm project DGS-Corpus.
DGS-Corpus is a long-term project by the Academy of Sciences in Hamburg.
Metadata Service
The metadata provided by the German National Library includes current and retrospective bibliographic data for individual series in the German National Bibliography, authority data from the Integrated Authority file, metadata from the German Union Catalogue of Serials, and data on new releases.

MONAPipe
MONAPipe stands for "Modes of Narration and Attribution Pipeline". It provides natural-language-processing tools for German, implemented in Python/spaCy.
Octra Backend
Web-based management tool for organizing transcription projects: audio files, transcribers, tools and assignments are managed in a graphical user interface.
OCTRA Transcription Editor
Web-based editor for orthographic transcripts. Octra provides different views of signal and transcript, supports a flexible organization of work, and provides tools to split signal files into segment-sized chunks.
OpenProject
The Project Management Service is a collaboration self service that allows you to manage and track your projects and source code repositories. By using DARIAH-DE OpenProject, users can independently coordinate their projects, keep track of their issues and document their results.

OWID
Das Online‑Wortschatz‑Informationssystem Deutsch (OWID) des IDS ist eine wissenschaftliche, korpusbasierte Plattform für verschiedene lexikografische Ressourcen wie Neologismen‑, Fremd‑ und Diskurswörterbücher.
OWID - Deutsches Fremdwörterbuch
Das Deutsche Fremdwörterbuch (DFWB) beschreibt und dokumentiert den zentralen Fremdwortschatz der heutigen gehobenen Alltagssprache sowohl in seiner gegenwärtigen Verwendung als auch in seiner historischen Entwicklung vom jeweiligen Entlehnungszeitpunkt an bis heute.
OWID - Neologismenwörterbuch
In diesem Wörterbuch finden Sie mehr als 2.100 neue Wörter, neue Phraseologismen sowie neue Bedeutungen etablierter Wörter, die zwischen 1991 und heute in den allgemeinsprachlichen Teil des Wortschatzes der deutschen Standardsprache eingegangen sind.
OWID - Protestdiskurs 1967/68
Dieses Wörterbuch ist das Nachschlagewerk zu der im Jahr 2012 erschienenen Untersuchung‚ Aspekte des Demokratiediskurses der späten 1960er Jahre.
OWID - Schlüsselwörter der Wendezeit
Die „Schlüsselwörter der Wendezeit“ wurden in den Jahren 1993–1996 am IDS mit dem Ziel erarbeitet, den öffentlichen Sprachgebrauch der Wendezeit in der DDR und in der Bundesrepublik konsequent korpusbezogen und textdokumentativ darzustellen.
OWID - Schulddiskurs 1945–55
Dieses Wörterbuch ist das Nachschlagewerk zu der im Jahr 2005 erschienenen Untersuchung zum Schulddiskurs in der frühen Nachkriegszeit. Es fasst die lexikalisch-semantischen Ergebnisse dieser Untersuchung in Form von Wortartikeln zusammen.
OWID – elexiko
elexiko ist ein Online-Informationssystem zur deutschen Gegenwartssprache, das den Wortschatz anhand aktueller Sprachdaten bis 2013 dokumentiert, erklärt und wissenschaftlich kommentiert.
OWID – Feste Wortverbindungen
Auf diesen Portalseiten finden Sie Ergebnisse erster konzeptioneller Überlegungen und praktischer Tests für eine neuartige korpusbasierte Mehrwortlexikografie in OWID (2001-2007).
OWID – Kommunikationsverben
Das Online-Nachschlagewerk Kommunikationsverben in OWID ist die elektronische Version des Handbuchs deutscher Kommunikationsverben.
OWID – Korpussuche
Die OWID-Korpussuche bietet Ihnen die Möglichkeit, unkompliziert und schnell authentische Korpusstellen aus den öffentlich zugänglichen Korpora des IDS in großem Umfang dynamisch abrufen zu können.
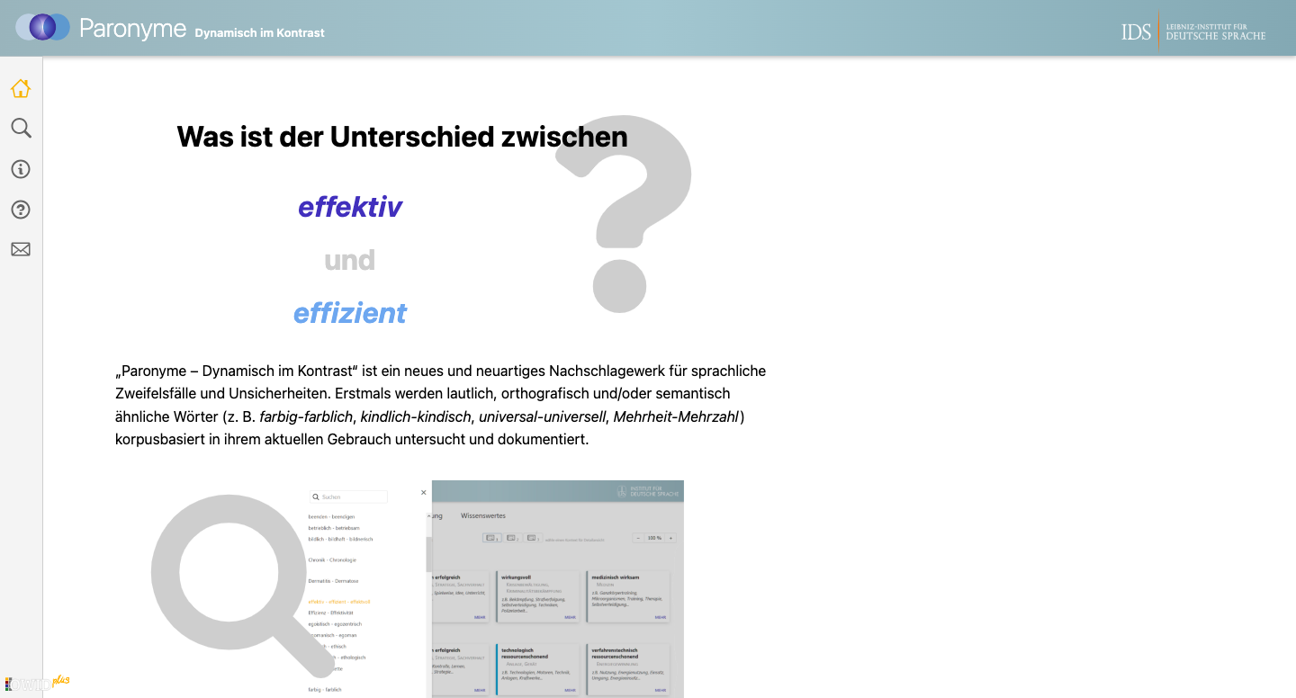
OWID – Paronymwörterbuch
„Paronyme – Dynamisch im Kontrast“ ist ein neues und neuartiges Nachschlagewerk für sprachliche Zweifelsfälle und Unsicherheiten. Erstmals werden lautlich, orthografisch und/oder semantisch ähnliche Wörter (z. B.
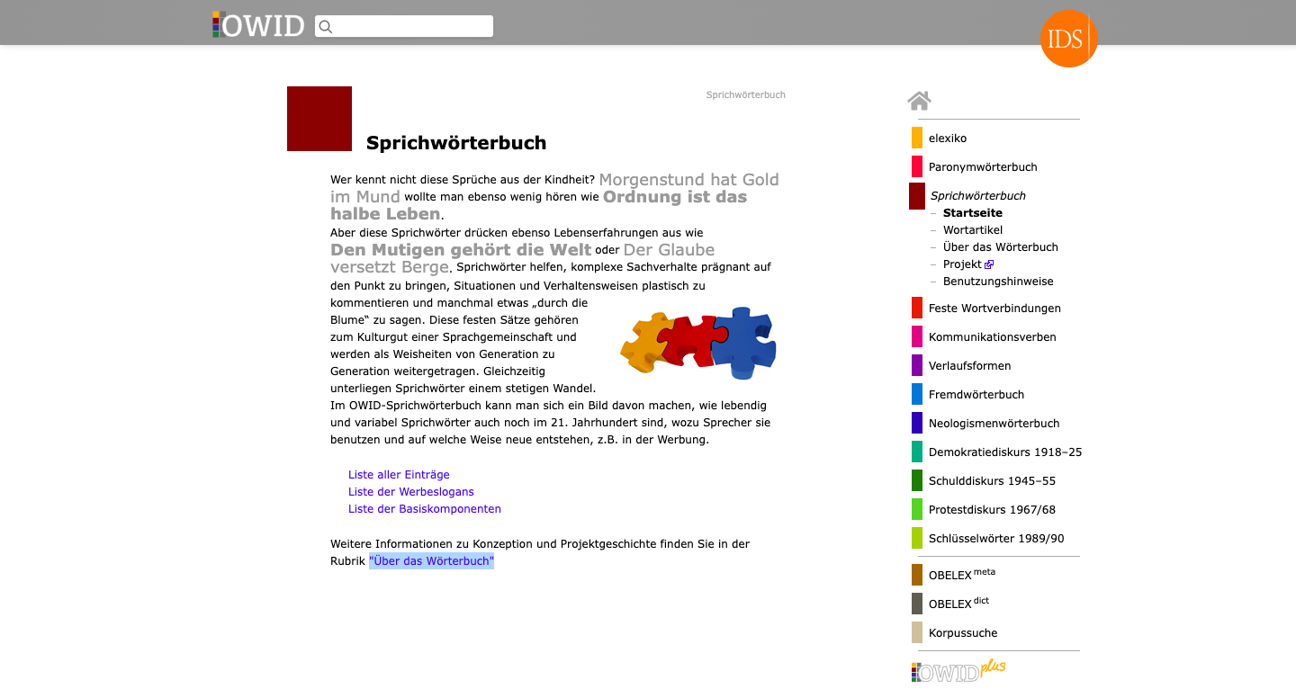
OWID – Sprichwörterbuch
Wer kennt nicht diese Sprüche aus der Kindheit? "Morgenstund hat Gold im Mund" wollte man ebenso wenig hören wie "Ordnung ist das halbe Leben". Aber diese Sprichwörter drücken ebenso Lebenserfahrungen aus wie "Den Mutigen gehört die Welt" oder "Der Glaube versetzt Berge".
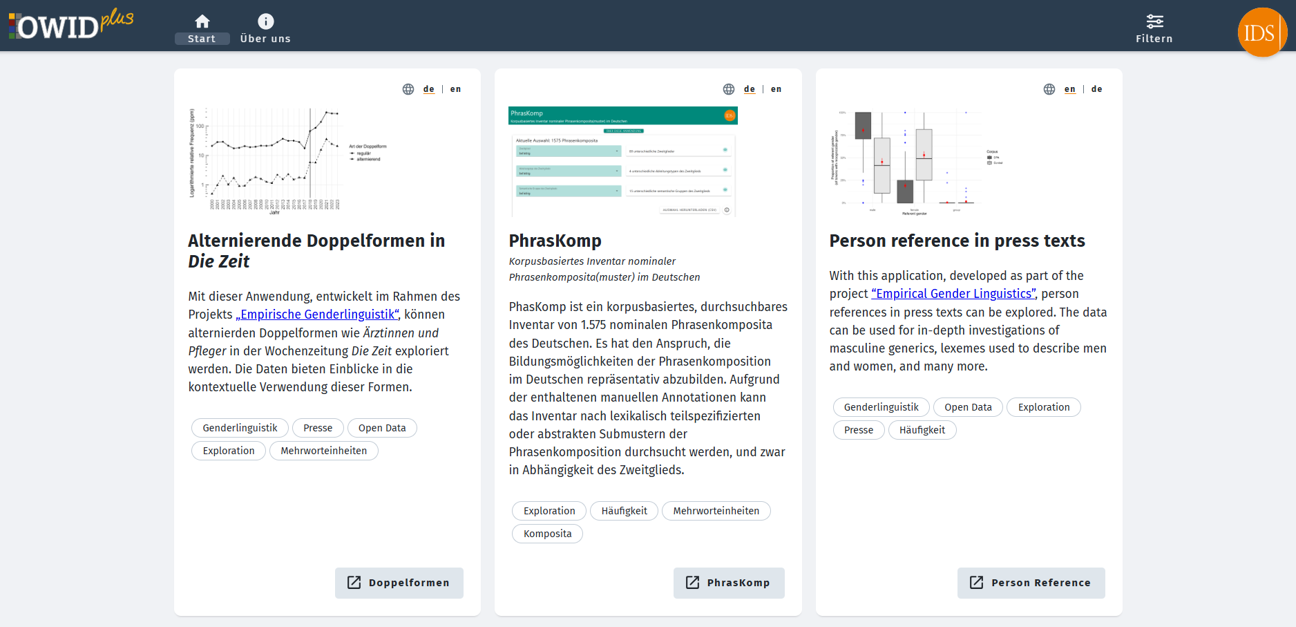
OWIDplus
OWIDplus ist eine experimentelle Plattform für multilinguale lexikalisch-lexikografische Daten, für quantitative lexikalische Auswertungen und für interaktive lexikalische Anwendungen, die in einzelnen unverbundenen Rubriken präsentiert werden.
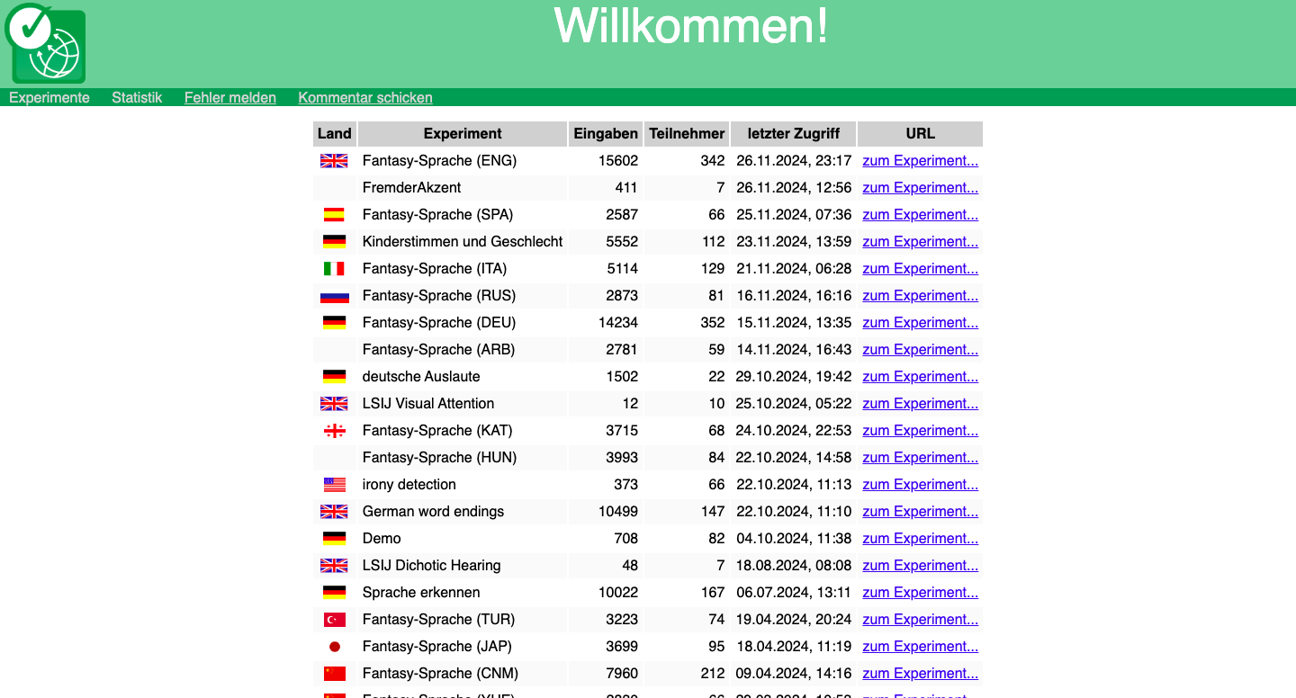
Persistent Identifier Service
In all aspects of research, the amount of digitally stored data is increasing continuously. Thereby the management will be more and more complex, so that the sustainable reference to data and thus their permanent censibility represent a challenge.
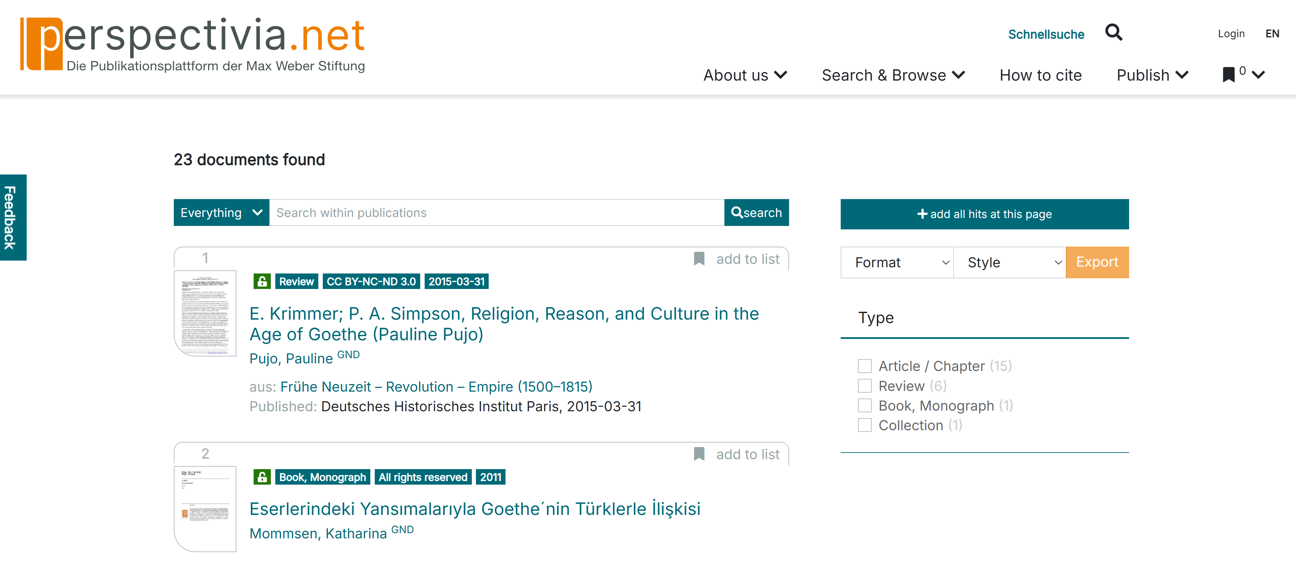
perspectivia.net
Scientific publications of the Max Weber Foundation (MWS, Max Weber Stiftung) and its partners can be published free of charge on the OA publication platform perspectivia.net in the sense of Diamond Open Access.
Portal Russlanddeutsch
Das Online‑Portal des IDS informiert über die deutsche Sprache in Russland und die Besonderheiten der Dialekte, die in Westrussland und in deutschen Sprachinseln der östlichen Sowjetunion gesprochen wurden.
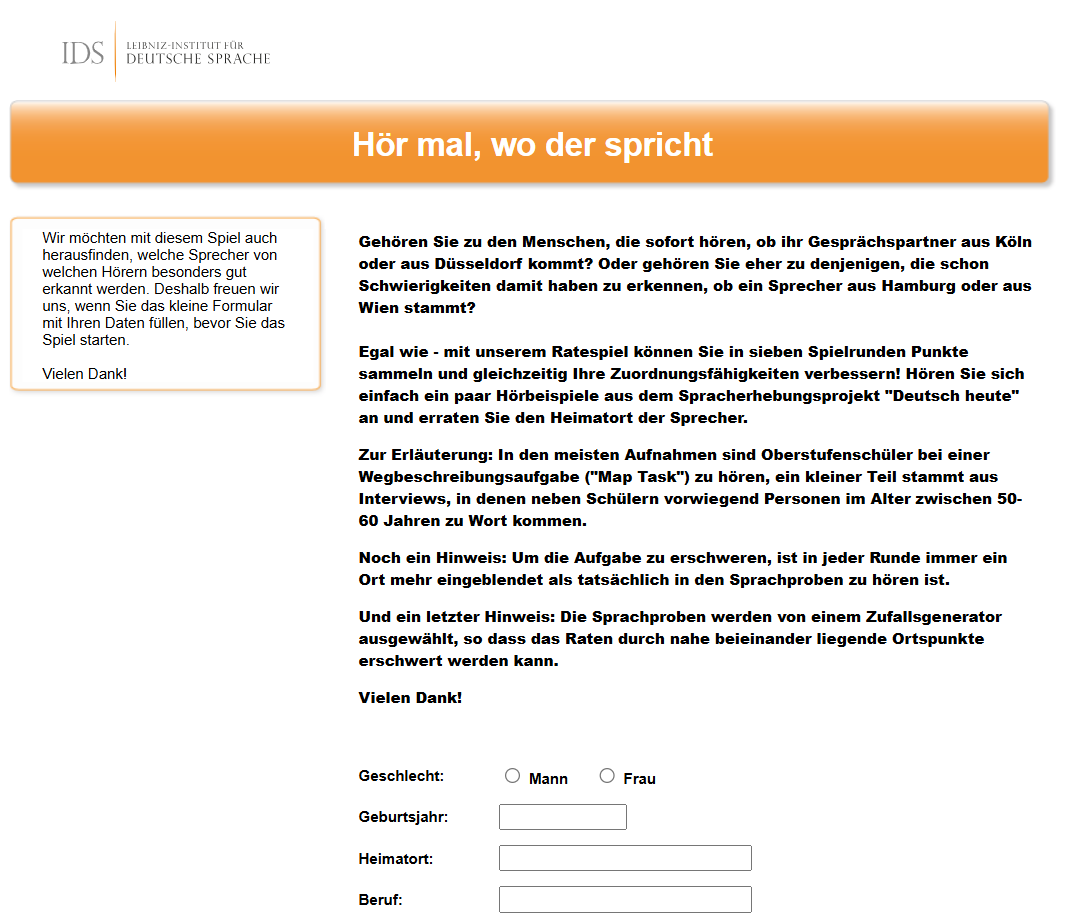
Ratespiel Hör mal, wo der spricht
Ein interaktives Hörratespiel des IDS ermöglicht es Nutzer:innen, Sprachproben anzuhören und den Heimatort der Sprecher zu erraten. Die Hörbeispiele stammen aus dem Spracherhebungsprojekt „Deutsch heute“. Jede Hörprobe kann beliebig oft wiedergegeben werden, um eine genauere Analyse zu ermöglichen.
RDMO in Text+
Text+ offers a questionnaire which is closely based on the standard catalogue of the Research Data Management Organiser (RDMO).

Russian Regions Acoustic Speech Database
The Russian Regions Acoustic Speech Database (RuReg) is a collection of speech recordings from various regions of Russia. Rureg aims to capture the diversity of accents, dialects, and speech characteristics across different regions of Russia.
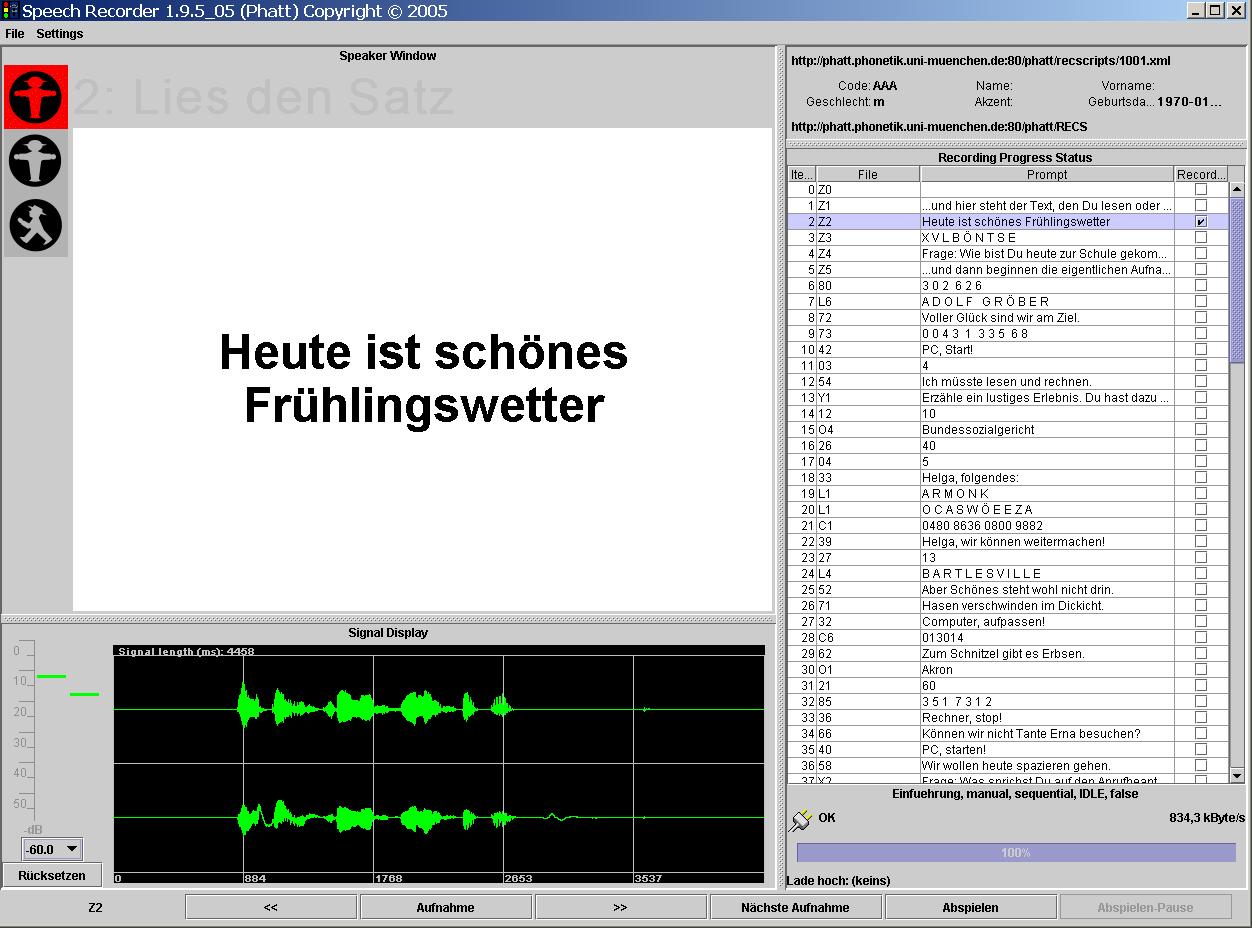
SpeechRecorder
Platform independent tool for performing scripted recordings. Flexible organisation of scripts into sections and groups for sequential or ordered recordings. Each utterance is saved in a separate file.
Text+ Curated Tool Platform for Editions (CSP)
Version 1.0 of a curated software platform for scholarly editions developed in Text+/NFDI is now available. The platform improves the visibility of software (and its authors) used in the field of scholarly editions.

Text+ Federated Content Search (FCS)
The Federated Content Search (FCS) is a specification and technical infrastructure for querying and aggregating distributed research data.
Text+ GitLab
Web-based source code management with a wide range of functionalities to support development processes. Configuration of continuous integration per project. Support for the merge request workflows. Consultancy and support in setting up your projects. Connection to the GWDG user administration.
Text+ Registry
Central, cross-domain research and information tool that records, correlates and links resources such as lexical resources, collections and editions. The Registry is not intended to replace existing directories and catalogs, but to complement them by offering a research-supporting 'one stop store'.
Text+ Web Portal
Web portal for Text+ based on HugoCMS and a CI/CD deployment pipeline. This resource is supported by Text+. In case of questions you may get in touch with the Text+ helpdesk at textplus-support@gwdg.de.
Text+ Zenodo Community
The Text+ Zenodo Community gathers a growing collection of affiliated research outputs, guidelines, project deliverables and other documents affiliated with Text+, the NFDI consortium for text- and langeuage-related research data.

TextGrid Repository & Laboratory
TextGrid is a virtual research environment for text-based humanities scholarship. It offers a variety of tools and services for collaboratively creating, analyzing, editing, and publishing texts.
tg-model - TextGrid Import Modeller
Whats the aim? This project focuses on attemps for a simple import of text corpora (encoded in XML/TEI) to TextGrid Repository by modeling the required metadata file structure.
tgadmin - TextGrid repository administration cli tool, based on tgclients
What is the aim? A command line tool for managing your projects in the TextGrid repository without TextGridLab.
The actual data import is finally carried out by the Python tools tgadmin and tgclients, which in turn communicate with the TextGrid backend via the various TextGridRep APIs.
tgclients - TextGrid Python clients
What is the aim?
The actual data import is finally carried out by the Python tools tgadmin and tgclients, which in turn communicate with the TextGrid backend via the various TextGridRep APIs.
TSAKorpus Hosting
Hosting of instances of multimodal/spoken corpora ANNIS Instances Language Corpora (i. e. multimodal Corpus of German Sign Language).
TüNDRA
TüNDRA is a web application for searching in 1004 treebanks for 173 languages such as treebanks for German and the full set of Universal Dependency treebanks. TüNDRA uses a lightweight query language based on TIGERSearch application.
TüNDRA Treebanks FCS Endpoint
FCS Endpoint which allows users to query TüNDRA treebanks from the Text+ Federated Content Search Aggregator. It does this by translating the FCS queries into the TüNDRA query language and returning the results.
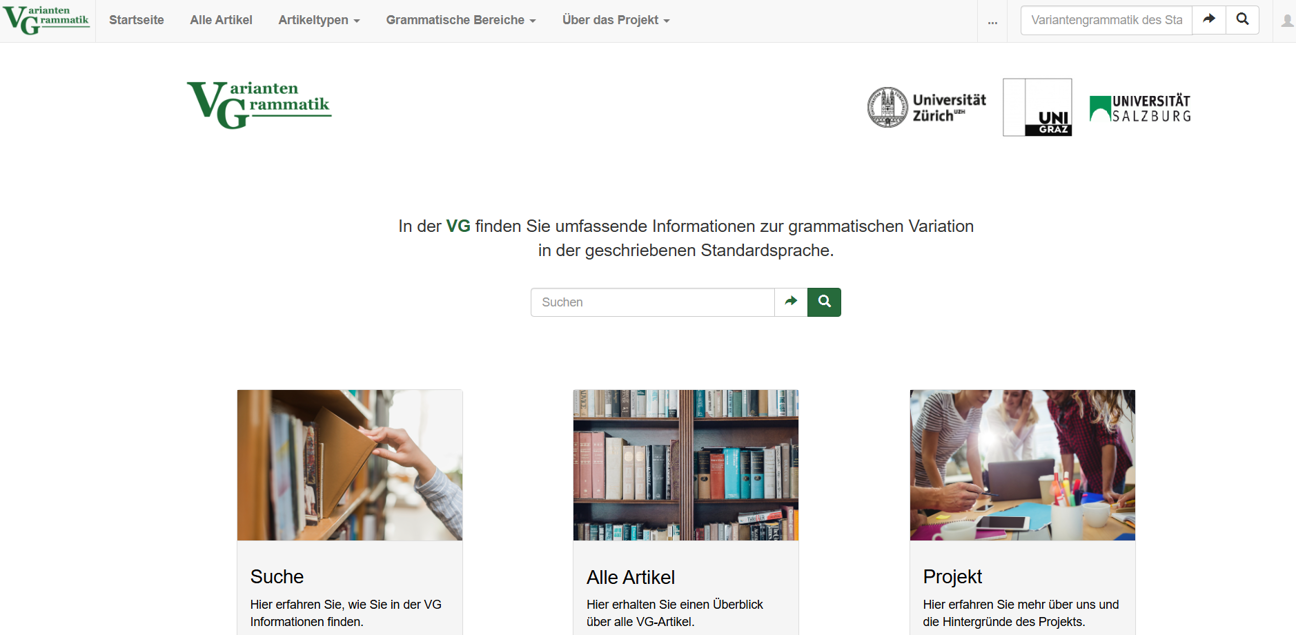
Variantengrammatik
Die VG bietet umfassende Informationen zum Vorkommen standardsprachlicher Variation. Sie gibt Nutzerinnen und Nutzern Hinweise darauf, wie sie sich in einem Land oder in einer Region im geschriebenen Standard unauffällig bewegen können.
WebLicht
WebLicht is an execution environment for automatic annotation of text corpora. Linguistic tools such as tokenizers, part of speech taggers, and parsers are encapsulated as web services, which can be combined by the user into custom processing chains.
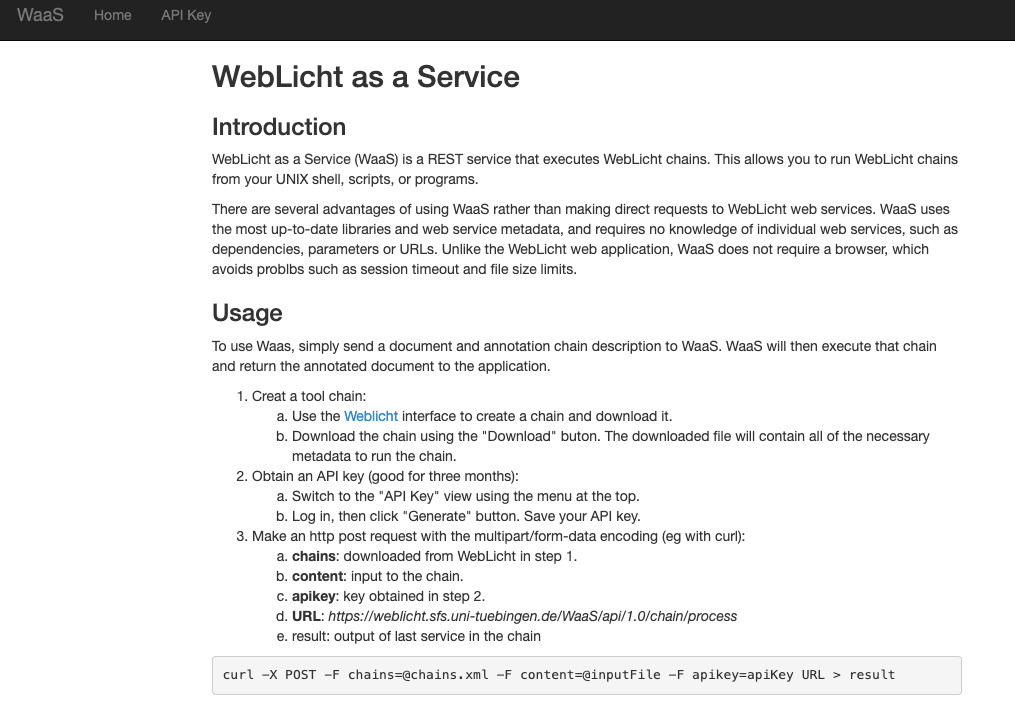
Weblicht as a Service
WebLicht as a Service (WaaS) is a REST service that executes WebLicht chains. This allows you to run WebLicht chains from your UNIX shell, scripts, or programs.
There are several advantages of using WaaS rather than making direct requests to WebLicht web services.
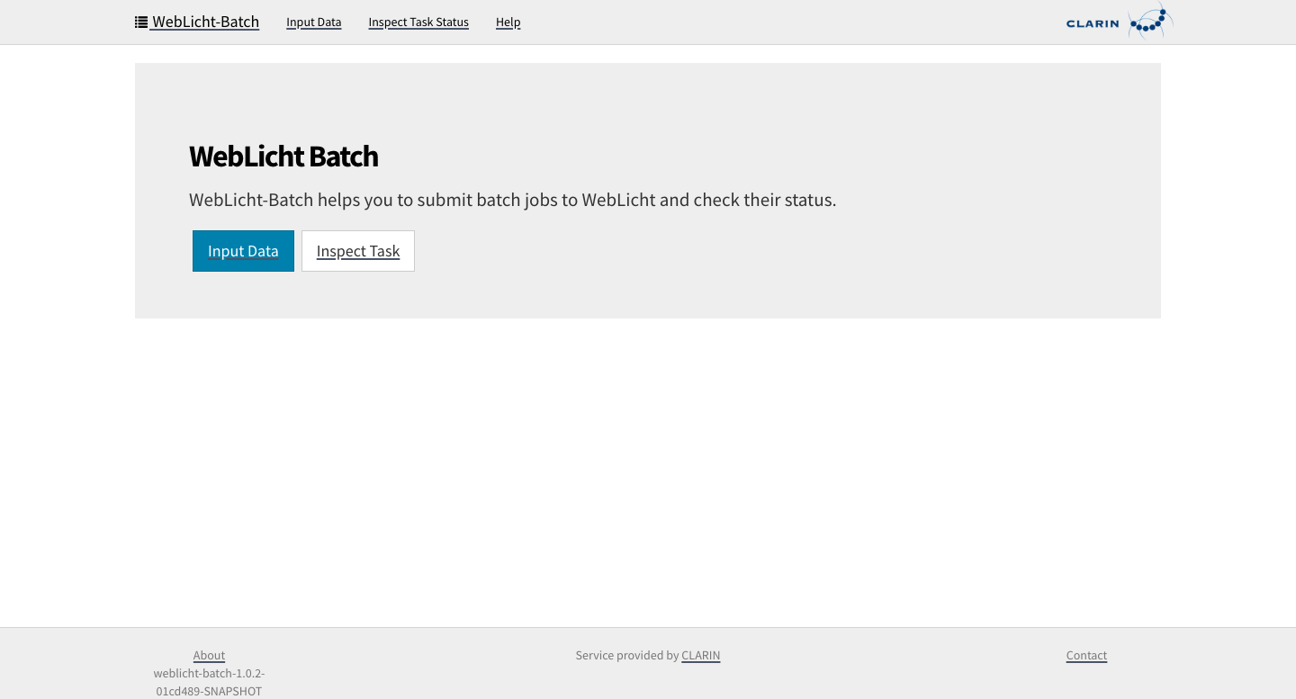
WebLicht Batch
WebLicht-Batch is a web-based interface to WebLicht’s chainer back-end. WebLicht-Batch helps users to automatically feed large input data, or input data of multiple files into WebLicht.
WebLicht Const Parsing EN
WebLicht Easy Chain for Constituency Parsing (English). The pipeline makes use of WebLicht's TCF converter, the Stanford tokenizer, and the statistical BLLIP/Charniak parser.
WikiSpeech
Web-based managment tool for scripted speech recordings via the Internet based on SpeechRecorder scripts.
What's it all about?
WikiSpeech is a content management system for the web-based creation of speech databases for the development of spoken language technology and basic research.
Richtlinien für die Beschreibung von Text+ Diensten im SSH Open Marketplace
Diese kurze Anleitung beschreibt, wie Dienste, die mit Text+ verbunden sind, im SSH Open Marketplace dargestellt werden können.
Servicedefinition
Die Sammlung von Ressourcen auf dieser Webseite umfasst neben genuinen Text+ Entwicklungen auch weitere Angebote der zu Text+ beitragenden Partner. Wie Dienste Teil des Text+ Angebots werden, ist Gegenstand der Text+ Services Policy, die als Version 0.9 Gegenstand projektinterner Diskussion und Weiterentwicklung ist.
Changelog
- upcoming: Differenzierung zwischen genuinen Text+ Angeboten sowie weiteren, für die Community relevanten Angeboten; Ergänzung von Förderkennzeichen in den Angebotsbeschreibungen
- Oktober 2025: Erweiterung auf 116 Einträge. Kuration bestehender Einträge. Kategorisierung der Einträge durch sechs Activities
- Oktober 2024: Erweiterung der Sammlung auf 79 Ressourcen. Anreicherung und Kuration bestehender Beiträge. Ergänzung der Text+ Services Policy v0.9
- Juli 2024: Verlinkung der Anleitung und Beschreibungsrichtlinie für Text+ Dienste im SSH Open Marketplace; Ergänzung eines Filterings nach Kategorien und Keywords
- Juni 2024: Erweiterung auf 35 Einträge sowie tlw. Überarbeitung individueller Beschreibungen sowie des Einleitungstextes dieser Seite
- Mai 2024: initiale Version einer Diensteliste mit 29 Einträgen