
Welcome!
We are pleased to present to you the first Text+ Newsletter. In the future, we will share news from the project up to four times a year in this section. We welcome feedback, questions, or requests, which can be easily sent to us via the Office (office@text-plus.org).
Why a Newsletter?
Text+ as an NFDI consortium aims to facilitate the use and preservation of text- and language-based research data. To achieve this goal, offers are being developed and established in collaboration with the community during the project’s runtime. Wherever sensible and possible, we build upon existing work or collaborate with other NFDI consortia. In addition to providing information about specific services and resources, we aim to inform about the current status of our work through instruments like the Newsletter. Lastly, we want to emphasize that Text+ is interested in feedback and community involvement.
Highlights from the Blog
In this section, we present interesting posts from the Text+ Blog. The blog provides comprehensive information about Text+ and, in addition to the website, also presents work in progress or allows for a detailed look at individual topics. All posts are equipped with DOIs and are citable.
Text+Plus, #05: From abejcejaŕ to źurja: Integration of Lower Sorbian-German dictionaries in the INSERT cooperative project
INSERT, a Text+ cooperative project from the first round, has presented a beautiful and informative blog post about the achieved results after one year of work. With the dedicated cooperative project called INSERT, four of the most important Lower Sorbian-German dictionaries were initially translated into the standard format TEI Lex-0 in 2023, to then be integrated into Text+’s digital infrastructures, especially the federated content search of the NFDI consortium. The project is assigned to the data domain Lexical Resources.
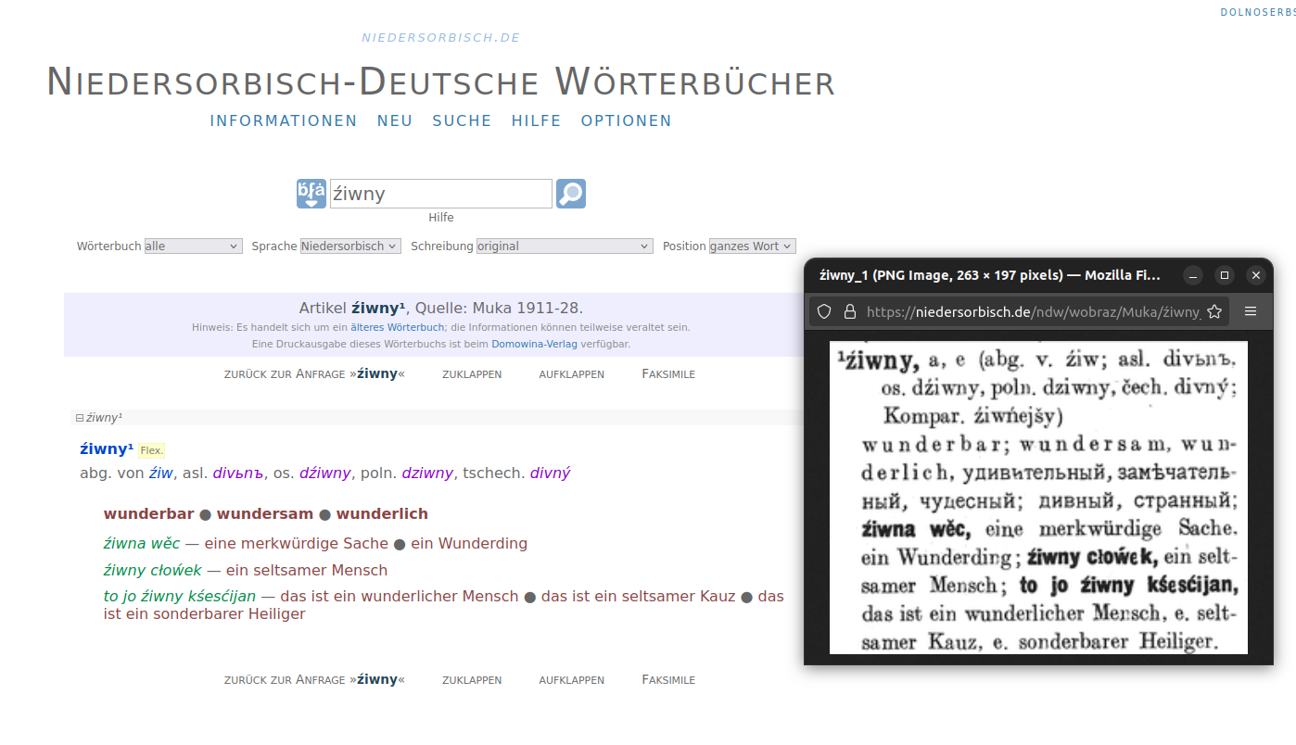
After the successful creation of the mapped data, these were integrated into Text+’s digital infrastructures. For this purpose, suitable metadata were initially created, including the registration of persistent handles. This enabled the resources to be included in the repository of the Saxon Academy of Sciences in Leipzig (SAW), one of the data centers for lexical resources of the NFDI consortium. In the SAW repository, the resources are archived and, to the extent permitted by their licenses, offered for direct download. Thanks to the provision of metadata via the OAI-PMH protocol, they can also be discovered in various aggregators.
To ensure that future updates of the representations of the dictionaries find their way into the infrastructures, a git-based ingest workflow was also developed, with which recorded innovations can be automatically tested and incorporated as dedicated releases into the SAW repository as separate versions.
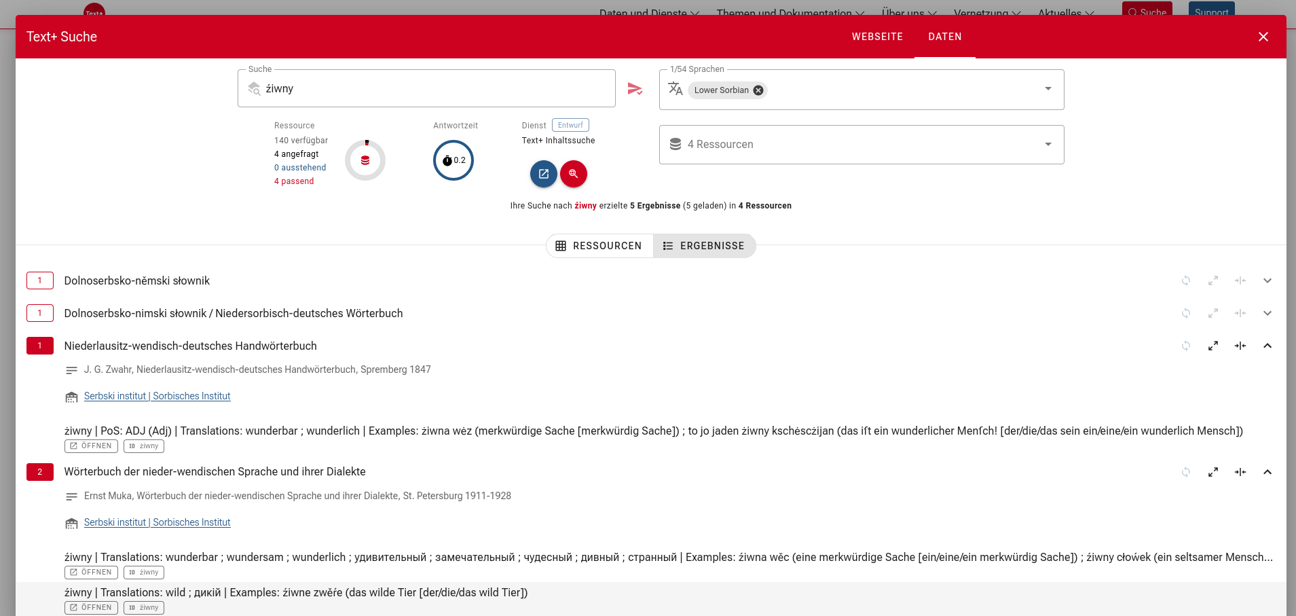
Another important connection is the import of data into an endpoint provided by SAW for the federated content search in Text+ (Federated Content Search, FCS). For this purpose, core information from the existing TEI Lex-0 XML data was transformed via XSLT and passed to the endpoint. The added value of this import? Through harvesters like the search mask on the Text+ web portal, the four dictionaries are now available as resources, whose contents can be searched with a differentiated query language (Erik Körner et al.: “Federated Content Search for Lexical Resources (LexFCS): Specification”. Zenodo 2023. DOI: 10.5281/zenodo.7986303).
Cite this blog post: Felix Helfer (2024, April 4). Text+Plus, #05: From abejcejaŕ to źurja: Integration of Lower Sorbian-German dictionaries in the INSERT cooperative project. Text+ Blog. Retrieved on April 23, 2024, from https://doi.org/10.58079/w5xm
Partner-Parade #02: The three-cornered hat of the German National Library in the Text+ consortium
The post introduces the triple role of the German National Library (DNB) in the Text+ consortium and its main areas of work. The DNB not only serves as the leading institution for the data domain Collections and one of its eleven certified data and competence centers but also provides, in collaboration with partners, the infrastructure for the Common Authority File (GND). Below is an excerpt from the blog article on the data domain Collections.
“Collections” is one of three data domains in Text+, focusing on collections of written, spoken, or signed language and on texts created based on scientific criteria. The coordination of the Collections data domain lies with the DNB.
It is responsible for building the distributed infrastructure in the data domain, such as by networking eleven certified data and competence centers, each specializing in content or specific data types. These centers, including the DNB itself, provide a wide range of text- and language-based research data on one hand, and offer archiving services for relevant data from research projects on the other, bringing them into the Text+ infrastructure to increase visibility and reusability for the scientific community.
A central component in the architecture of the project is the Text+ Registry. This is a discovery system that makes resources in Text+ findable, interconnects them, and ensures connectivity to other infrastructures (e.g., EOSC, OPERAS, and of course within the NFDI). Under the leadership of the DNB, a common data model was developed in the Collections data domain, allowing all data centers to uniformly describe the collections they bring into the Text+ infrastructure. Emphasis was placed on using controlled vocabularies and standard data like the GND (see below), as they increase the degree of interconnection and interoperability of collections among themselves and also with lexical resources and editions in the registry.
Many of the collections are also searchable in full text. With the Federated Content Search (FCS, here the prototype), Text+ offers a central search entry point, allowing researchers to perform full-text and complex searches across currently more than 50 resources simultaneously – a significant time saver in compiling corpora and an expansion of the search space to sources that might otherwise be overlooked
Many collections are also searchable in full text. The Federated Content Search (FCS) provides a central search entry point, allowing researchers to perform full-text and complex searches across more than 50 resources simultaneously – a significant time saver in compiling corpora and expanding the search space to sources that might otherwise be overlooked. The DNB has contributed the German Newspaper Portal, with its 20 million historical newspaper pages now searchable via the FCS. Next, the title data of the DNB and extensive full-text collections, such as free online theses, will be integrated into the FCS.
Workshop Reports
Text+ Architecture
The Task Area Infrastructure Operations presented the Text+ architecture in version 1.0 during the spring meeting at the German National Library. This provides a functional view of Text+ and shows essential technical components along their functions. It does not offer a comprehensive representation of all technical components or APIs nor map all data paths precisely but focuses on functionality. In the long run, the architecture aims to contribute to the joint discussion of the further development of Text+ within the NFDI. Other consortia with humanities and cultural science target groups are particularly important for Text+. Other infrastructure contexts, such as the Base4NFDI initiative or the SSH Open Marketplace, are also considered from the beginning.
The Text+ architecture is subject to continuous development and will be provided in version 1.1 after a joint meeting of the Coordination Committees on June 3.
Text+ Cooperation Projects
Text+ Cooperation Projects Funding 2023
In the first funding round of Text+ in 2023, ten promising and innovative cooperation projects were supported. The funding started in January 2023 and ran until the end of the year. The funded projects covered a wide range of topics:
- Pessoa digital (University of Rostock) for the sustainable design of the digital edition “Fernando Pessoa. Projects and Publications” with subsequent integration into the Text+ research data infrastructure.
- edition2LD (Heidelberg Academy of Sciences) for developing a workflow for modeling text edition data as Linked (Open) Data in the Resource Description Framework. More information on the project can be found here.
- FriVer+ (Leibniz Institute of European History) for providing (meta-)data on more than 1800 early modern bi- and multilateral European peace treaties in a standardized and reusable XML/TEI format. More information on the project can be found here.
- INSERT (Sorbian Institute) for integrating four Lower Sorbian-German dictionaries into the Text+ research infrastructure. More information on the project can be found here.
- CGLO (Bavarian Academy of Sciences) for converting the reference work Corpus Glossariorum Latinorum (published 1862-1923 in 7 volumes) into a lemmatized database with integration into the Text+ research infrastructure.
- MWB-APIplus (Middle High German Dictionary, Trier Office of the Academy of Sciences and Literature Mainz and Middle High German Dictionary, Göttingen Office of the Academy of Sciences of Lower Saxony) for creating a technical interface for the Middle High German Dictionary with integration into the Text+ data portfolio. More information on the project can be found here.
- KOLIMO+ (University of Bielefeld) for optimizing and enriching the Corpus of Literary Modernity with subsequent integration into the Text+ services.
- DiPA+ (German Institute for Adult Education - Leibniz Centre for Lifelong Learning) for integrating the retro-digitized holdings of the Digital Program Archive of German Adult Education Centers into the Text+ infrastructure.
- DLA Data+ (German Literature Archive Marbach) for providing open access to the data of the German Literature Archive Marbach for sustainable reuse via the Text+ infrastructure. More information on the project can be found here.
- Diskmags (Bergische Universität Wuppertal) for developing re-digitalization methods for texts from German-language disk magazines and formulating best practices for digital text reconstruction from old file formats.
We thank all the projects for their cooperation during the funding period! The variety of topics and the milestones achieved reflect the commitment and expertise of all involved. We look forward to seeing the results of these projects in the Text+ research data infrastructure and sharing the insights within the scientific community.
Text+ Cooperation Projects Funding 2024
On January 1, 2024, the funding of new cooperation projects began. In spring 2023, 19 diverse and exciting projects with a total funding requirement of 1 million euros were submitted, all of which were of high quality. Since this amount exceeded the available budget fourfold, a selection had to be made, which was not an easy decision. Four projects were selected for funding, which we warmly welcome to Text+:
- Project “The Beria Collection in the Language Archive Cologne: Expansion, revision, and evaluation of a data collection of an under-described African language” submitted by Prof. Dr. Birgit Hellwig, Dr. Isabel Compes (University of Cologne, Institute of Linguistics) in the Task Area Collections.
- Project “Thesaurus Linguae Aegyptiae – More Fair with APIs” submitted by Dr. Daniel Werning (Berlin-Brandenburg Academy of Sciences and Humanities, Center for Basic Research Ancient World) in the Task Area Lexical Resources.
- Project “The Oldest Görlitz Town Book 1305-1416: Transformation, Curation, and Dual Digital Publication (Data, Web Application) of an Exceptional Book Edition for Historical Disciplines” submitted by Prof. Dr. Patrick Sahle, Dr. Christian Speer (Bergische Universität Wuppertal / Martin-Luther-Universität Halle-Wittenberg) in the Task Area Editions.
- Project “Tool Support for Automatic Extraction of Tabular Data from Historical Newspapers” submitted by Prof. Dr.-Ing. Frank Krüger (University of Applied Sciences Wismar) in the Task Area Infrastructure/Operations.
Publications, Services & Information Offerings
Text+ maintains its bibliography on Zotero and presents a structured view on its portal.
Onboarding Guide of the Data Domain Editions
We would like to introduce the Onboarding Guide published by the Data Domain Editions:
- Hensen, K. E., Speer, A., Geißler, N., Sievers, M., Kudella, C., Lemke, K., & König, S. (2024). Onboarding Guide der Task Area Editions (Version v1). Zenodo. https://doi.org/10.5281/zenodo.10854729
The Onboarding Guide, organized by offerings, explains how institutions and researchers can get involved. For example, it addresses integrating new data sets into the Text+ portfolio.
Funding Approval for Jupyter4NFDI
Text+ is pleased about the funding approval for Jupyter4NFDI, a basic services application submitted by the two data centers Jülich and GWDG involved in Text+!
Additionally, DMP4NFDI and KGI4NFDI, two other basic services, are funded in the initialization phase by Base4NFDI.
Events & Reports
Text+ at DHd2024
At DHd 2024 from February 26th to March 1st, 2024 in Passau, Text+ was represented in various talks and poster presentations. For the first time this year, there was a joint information stand with the NFDI consortia of the so-called Memorandum of Understanding group: NFDI4Culture, NFDI4Memory, NFDI4Objects, and of course, Text+. In the MoU group, exchange and partial collaboration on various topics take place.
Text+ Spring Meeting on March 12 and 13, 2024 in Frankfurt am Main
On March 12 and 13, the NFDI consortium Text+ gathered for its spring meeting at the German National Library (DNB) in Frankfurt am Main. The first day of the spring meeting was characterized by thematic working meetings focusing on various aspects. These included discussions on the further development of the Text+ architecture, particularly the analysis of the essential technical components and their functions. The current status of the Text+ Registry, a central component of the project that improves resource discoverability and enables seamless integration with other infrastructures, was also presented. Additionally, the ingest processes in the Text+ data centers were examined, aiming to make them transparent and user-friendly, with discussions on topics such as data formats, quality assessment, licensing, and the merging of users and data centers. On the second day of the meeting, the focus was on the meetings of the Text+ Task Areas, where specific working areas were discussed in depth. Overall, this year’s spring meeting was highly productive and provided valuable impetus for the further development of Text+.
Sustainable Archiving, Indexing, and Providing Dynamic Data from Social Media – Twitter and Beyond
The aim of this conference on March 19 and 20, 2024, at the DNB in Frankfurt am Main was to network libraries, archives, research institutes, and researchers in the German-speaking area who are involved in the archiving and sustainable use of data and digital objects from social media. Archiving, indexing, and providing these dynamic data face challenges that affect all these actors equally, and ideally, joint solutions should be developed.
The cross-sectional nature of the topic is demonstrated not only by the great interest of the conference participants – over 160 people had registered – but also by the involvement of numerous NFDI consortia that were represented on the program committee and co-organized the conference. In addition to Text+, these included BERD@NFDI, KonsortSWD, NFDI4Culture, NFDI4Data Science, and NFDI4Memory.
The program and many of the conference presentations can be accessed in the public DNB-Wiki.
Codesprint for Humanities Data

On April 11 and 12, a Codesprint for Humanities Data was held at the SUB Göttingen. This event was organized by Measure 5 of Task Area IO together with the Data Domain Collections, and aimed to test the import workflow for new research data collections into the TextGrid Repository with the participants. With the new import workflow – and some other new features – the TextGrid Repository is a useful place for archiving text-based research data.
Dates
| Date | Event | Location |
|---|---|---|
| April 25, 2024 | 9th IO-Lecture: TextGrid Repository | virtual |
| April 30, 2024 | Text+ Research Rendezvous | virtual |
| May 21, 2024 | Bridging Neurons and Symbols for Natural Language Processing and Knowledge Graphs Reasoning | Turin |
| May 29, 2024 | 10th IO-Lecture: The TextGrid Repository & the Core Trust Seal | virtual |
| June 3, 2024 | First Joint Meeting of all Coordination Committees of Text+ | virtual |
| June 20, 2024 | 11th IO-Lecture: The Base Classification in the User Stories of Text+ | virtual |
| June 24, 2024 | Edit-a-thon on Describing Resources in the SSH Open Marketplace | Bonn |
| June 27-28, 2024 | Understanding Speech: AI and Spoken Language | Munich |
| October 10-11, 2024 | 3rd Text+ Plenary | Mannheim |