
Welcome!
Here is the Text+ newsletter for December 2024. We cordially invite you to take a look at our project activities. We welcome any feedback, questions, or requests, which can be most easily directed to us via the office.
Currently, we distribute the newsletter every three months through various channels: via the website and through our email list to the community that wishes to stay updated about Text+. This list currently includes 400 recipients. If you would like to receive the newsletter through this channel, please let us know briefly.
Text+ Internal
Change of Speaker
On October 1, 2024, Prof. Dr. Andreas Witt took over the position of spokesperson for the NFDI consortium Text+ from Prof. Dr. Erhard Hinrichs. As part of this transition, the long-standing contributions of Erhard Hinrichs were acknowledged, recognizing his significant role in the successful establishment of the consortium.
Andreas Witt brings extensive experience and new perspectives to the role, aiming to actively shape the future challenges and opportunities of Text+. We thank Erhard Hinrichs for his exceptional dedication and wish Andreas Witt every success in his new role.
Results of Coordination Committees Elections
In November 2024, elections were held for the Coordination Committees (CC) of Text+ for the 2025/2026 term. The CCs consist of three Scientific Coordination Committees, each covering one of the data domains – Collections, Editions, and Lexical Resources – as well as the Operations Coordination Committee for the Task Area Infrastructure/Operations. Their main task is to support the development of the portfolio of data, tools, and services through evaluation and feedback.
CC members are elected for a two-year term. Following a remarkably high number of nominations, the election process began, adhering to the procedural guidelines for the appointment of Coordination Committees in Text+. Eligible voters included representatives from professional associations and networks supporting Text+, as well as institutions that are part of the Text+ consortium.
Voter turnout was 68.23%. After the election process concluded and the elected members accepted their roles, the results were officially announced on December 4, 2024. The elected members will be featured on the consortium’s website in early 2025.
We thank all candidates for their willingness to stand for election and warmly congratulate the elected members. We look forward to a successful collaboration in the upcoming term.
Acknowledgment to the Members of the Coordination Committees for the 2023/2024 Term
At this point, we would like to express our heartfelt thanks to all CC members who will be stepping down from their roles at the end of the current term. Your commitment has enriched and shaped the work of Text+. A special thank you goes to the chairs and vice-chairs of the committees, whose efforts over the past two years have played a crucial role in advancing the goals of the consortium. Without them, the evaluation of the cooperative projects would not have been as qualified and effective. We deeply appreciate your time and energy and wish you all the best for the future!
Blog Highlights
In this section, we present interesting posts from the Text+ blog. The blog provides information about Text+ and supplements the website by offering work in progress or a closer look at individual topics. All posts are DOI-enabled and citable.
Guest contributions on topics of interest to the Text+ community are warmly welcome! Get in touch if you have a topic.
Call for Contributions for the Workshop “Text+: Enriching Digital Research Based on Text and Language Data” at the DHd Conference 2025 in Bielefeld
As part of the Digital Humanities conference in the German-speaking region (DHd) at the University of Bielefeld, the workshop “Text+: Enriching Digital Research Based on Text and Language Data” will take place on March 3-4, 2025. This hands-on workshop will provide an overview of Text+’s offerings and, in collaboration with the community, will identify open needs.
The workshop organizers encourage participants to address their needs to Text+ in advance, particularly those that go beyond the existing offerings. These might include new tools, software pipelines, data storage solutions, guidelines, training opportunities, and much more. Also welcome are suggestions for expanding existing offerings with additional features and capabilities.
Short abstracts of a maximum of 500 words are invited, outlining a desideratum in Text+’s service portfolio, justifying its relevance for research, and providing perspectives on how the open need can be addressed.
Five submissions will have the opportunity to present their needs in the workshop through a brief presentation (max. 10 minutes) and engage in a discussion with the participants. All submissions are also invited to contribute a poster that visually outlines their needs.
Abstracts will be accepted until February 19, 2025, 23:59 CET at office@text-plus.org.
Citing this blog post: Text+ Blog Editorial Team (December 17, 2024). Call for Contributions for the Workshop “Text+: Enriching Digital Research Based on Text and Language Data” at the DHd Conference 2025 in Bielefeld. Text+ Blog. Retrieved December 20, 2024, from https://doi.org/10.58079/12y47
Edit recommends #1: The Great Family Book of Philipp Hainhofer
The practice of keeping a Stammbuch, also known as an “Album Amicorum” or “Friendship Book,” was very popular around 1600. The so-called Große Stammbuch (Great Friendship Book) of the Augsburg art dealer and agent Philipp Hainhofer (1578–1647) gathers entries, dedications, and coats of arms from high-ranking personalities spanning the years 1596 to 1633. Hainhofer’s Großes Stammbuch is notable for its collection of loose, non-chronological, and rather rank-ordered single and double sheets made of parchment and paper, containing entries from princes (including two emperors!) and nobles, as well as many decorated pages. The book served as a collection of art, a record of contacts, and a tool for both business and social practices. The valuable object was acquired in 2020 for the Herzog August Library. This acquisition was accompanied by a research project aimed at thoroughly exploring the Stammbuch and making it accessible to the public. One of the outcomes of this project is the annotated digital edition Philipp Hainhofer · Das Große Stammbuch.
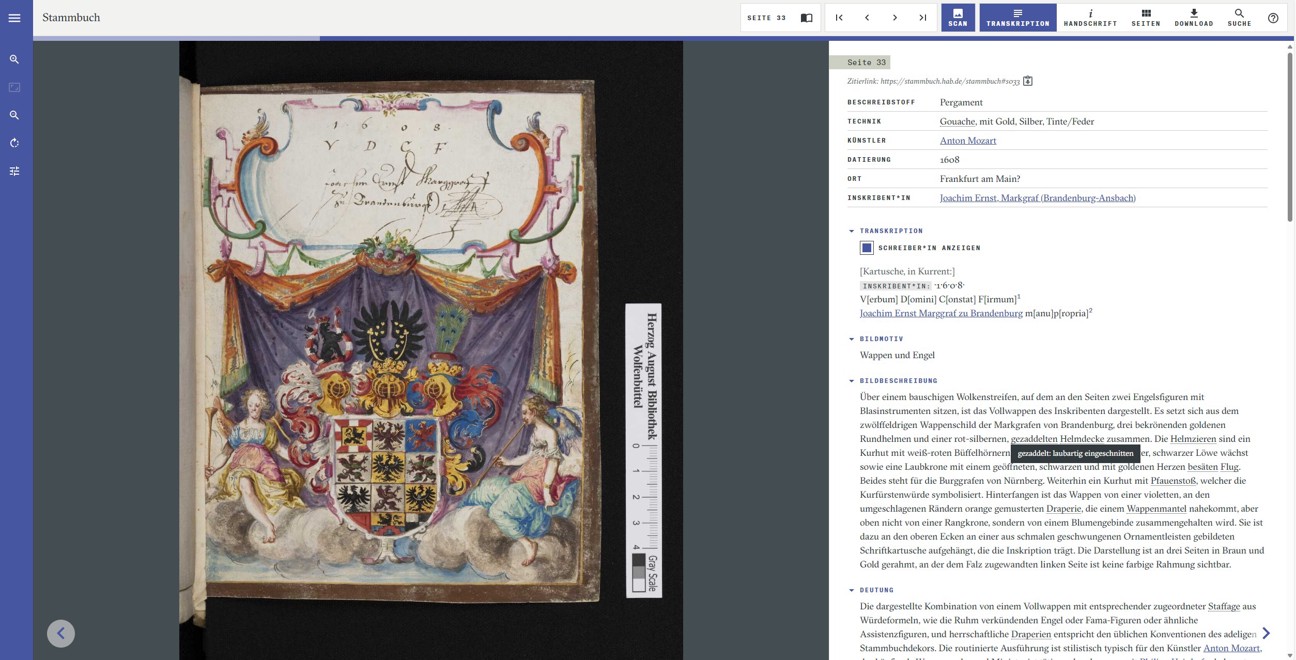
Please continue reading on the Text+ Blog.
Citing this blog post: Kathrin Henseleit, Martin de la Iglesia, Sabine Jagodzinski: Edit recommends #1: Das Große Stammbuch Philipp Hainhofers (Ressourcen-Reigen Spezial). Text+ Blog, November 12, 2024, https://textplus.hypotheses.org/11489.
Workshop Reports
Core Trust Seal for the TextGrid Repository
The TextGrid Repository is a digital long-term archive for humanities research data, providing an extensive, searchable, and reusable collection of texts and images. It is aligned with the principles of Open Access and the FAIR (Findable, Accessible, Interoperable, Reusable) principles, focusing on texts in XML TEI to support a wide range of reuse scenarios. For researchers, the TextGrid Repository offers a sustainable, permanent, and secure way to publish their research data in a citable manner and to describe it clearly through metadata. More information on sustainability, FAIR, and Open Access can be found in the TextGrid Repository’s Mission Statement.

The CoreTrustSeal (CTS) is an international, non-profit organization with the goal of promoting trustworthy data infrastructures. It certifies repositories based on the Core Trustworthy Data Repositories Requirements, which assess the core competencies of trustworthy repositories. After a certification application is submitted, it is reviewed by a panel of international evaluators. The CoreTrustSeal certification is one of the most recognized certifications and is internationally acknowledged, as evidenced by the list of certified repositories.
The requirements catalog is divided into 16 different criteria and includes questions about the organization behind the repository, digital object management, and technical and security aspects. These include, for example, a mission statement, legal and ethical considerations, documentation of workflows, metadata standards, and technical infrastructure. A repository may only carry the CoreTrustSeal certificate if it meets all of the criteria. In the certification of the TextGrid Repository, particular praise was given for its comprehensive general documentation and its API documentation. At the same time, it was highlighted that the quality of metadata and the implementation of the designated community’s needs played such an important role in the design of the TextGrid Repository.
Further content-related information about the TextGrid Repository can be found in the documentation section of the TextGrid website, with technical details available on the repository server’s documentation page.
Application examples
For FAIR research data, adherence to established and widely used standards for object and metadata is essential. In particular, to ensure findability, interoperability, and reusability in a distributed infrastructure like that of Text+, uniform formats and standards across repositories are indispensable. Text+ provides a dedicated section on its portal with information, resources, and examples related to the standardization of research data.
Newly added are practical use cases from the data domains and cooperation projects. The featured projects from the fields of text and language sciences successfully employ standards and standard-based tools recommended by Text+:
- correspSearch – Searching and linking letter editions
- The German Reference Corpus (DeReKo)
- German Text Archive (DTA)
- edition humboldt digital
- Klaus Mollenhauer Complete Edition (KMG)
- Text+ cooperation project INSERT
In 2025, a series of workshops will be offered around these use cases, where projects can be presented and discussed. Registration for the first event on March 20: DTABf - The German Text Archive Basic Format is already open.
Publications, Services & Information Offers
Text+ maintains its bibliography on Zotero and presents a structured view on its Portal.
The interoperable edition ‘sub specie durationis’
We would like to introduce an article from the journal editio:
- Hegel, Philipp, Tessa Gengnagel, Kilian Hensen, Karoline Lemke, and Gerrit Brüning. “Die interoperable Edition sub specie durationis.” editio 38, no. 1 (November 1, 2024): 135–46. https://doi.org/10.1515/editio-2024-0008.
This article examines the role of specific data formats as intermediaries between project-specific data models and interconnected digital resources. The potential of pivot formats and the BEACON format are particularly highlighted. By taking a closer look at various formats and software tools for data preparation, transformation, and analysis, the authors demonstrate how additional machine-readable formats can enhance the longevity and interoperability of digital editions.
Events & Reports
Webinar on the legal aspects of collecting and sharing social media data
On November 25 CLARIN-CH (the Swiss CLARIN consortium) organised a webinar on Legal aspects of collecting and sharing social media data, with an invited presentation by Dr. iur. Paweł Kamocki, legal expert at Leibniz Institute for the German Language in Mannheim and co-chair of the Text+ WG Legal. His presentation discussed the legal challenges surrounding the use of social media data for language research purposes, covering essential topics such as copyright and text-and-data mining (TDM) exceptions, the importance of terms of service, data protection laws, as well the new regulatory framework under the Digital Services Act. The slides and the recorded presentation can be found under this link: https://clarin-ch.ch/news/2024/10/22_1729589265
Text+ FID Jour Fixe
Specialised information services and the NFDI have partly comparable goals. For this reason, Text+ and specialist information services associated with Text+ met for the fifth time on 27 November for the regular FID/Text+ Jour fixe, this time in the presence of the Göttingen State and University Library (https://events.gwdg.de/event/960/).
The focus was on three major topics: the Text+ Registry and its design, to which specialised information services were able to provide valuable input from their communities; data depositing as a topic for all the communities represented by those present, as well as examples of the depositing services offered by the Text+ data centres; and the objectives of the JF, which was organised and themed jointly by FIDs and Text+ for the first time. There was also plenty of time for other topics (e.g. the joint translation of the basic classification or greater mutual support in the acquisition of funding) and discussions. The JF was thus able to make a further contribution to the deeper integration of both structures and it was agreed that it should be continued at regular intervals.
Special thanks go to those responsible for the organisation from FIDs and the Text+ AG FID Koop as well as the SUB Göttingen as host. A blog post with a detailed review is in preparation.
Entity Linking, a Text+ IO Lecture
On September 18, 2024, the 16th Text+ IO-Lecture took place, this time on the topic of Entity Linking. The Text+ IO-Lectures are open to all interested parties and focus on infrastructure-related topics. IO in Text+ plays a provider role and, in collaboration with other Task Areas, identifies scientific needs for Text+ offerings. This results in a demand for information and advice, which IO addresses through the regular, low-threshold series of IO-Lectures. In addition, the IO-Lectures cover topics that are of interest beyond Text+ and to the NFDI, as well as to research infrastructures in general.
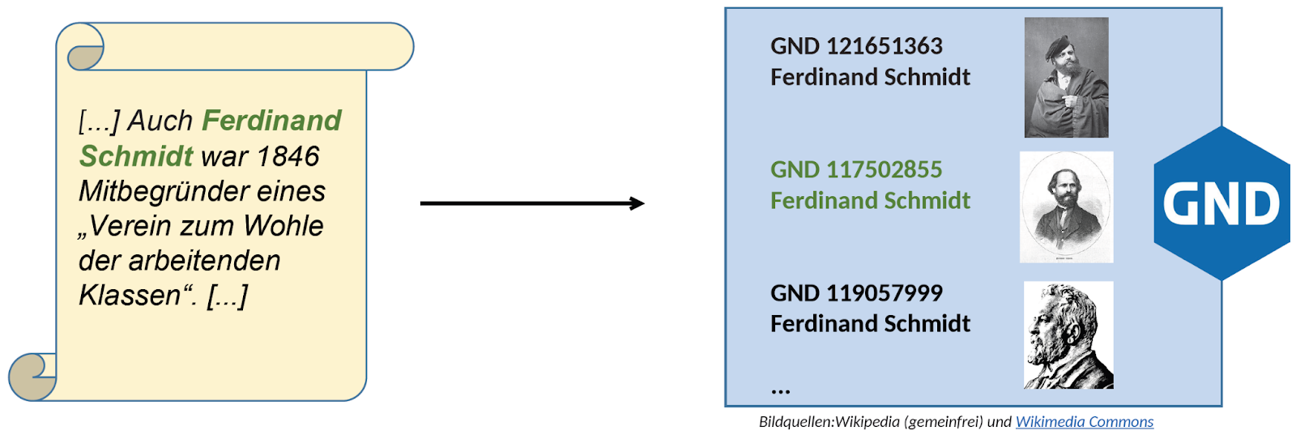
After a brief introduction to the topic by Felix Helfer (SAW), Alexander Bartmuß (SAW) presented a dataset under development, for which Entity Linking plays a central role: the “Letters and Documents on the Church Politics of Frederick the Wise and John the Steadfast 1513–1532” from the corresponding project at SAW. The participants of the lecture were given an insight into the project, particularly the work steps, advantages, and challenges involved in manually linking the entities that appear in the texts. While enriching text-based data in this way is highly valuable, the actual implementation of this process can be very labor-intensive.
If manual processing is not feasible, automatic Entity Linking methods could be of help. But how reliable are existing solutions, especially for German research data? Pia Schwarz (IDS) presented her benchmark, which evaluates the performance of existing tools. The conclusion from the benchmark: Quality in all cases is definitely improvable!
Furthermore, an ongoing investigation of an LLM-based approach via prompting was presented, exploring potentially better future solutions. In this approach, different candidates, including descriptions of an entity from a knowledge base, are first extracted, and then an LLM is prompted to disambiguate them. Initial experiments have shown that the results are better than the models that were previously evaluated.
This hope was the starting point for the second part of the lecture, which focused mainly on ongoing work within Text+ on the topic of Entity Linking. First, experiments with “Entity Embeddings” on data from the Leipzig Wortschatz corpus were presented. In this approach, embeddings for GND entities are generated from contextual data (specifically: Wikipedia articles about the respective entities), which can then be compared with embeddings of entities in an input text and their context using common similarity metrics.
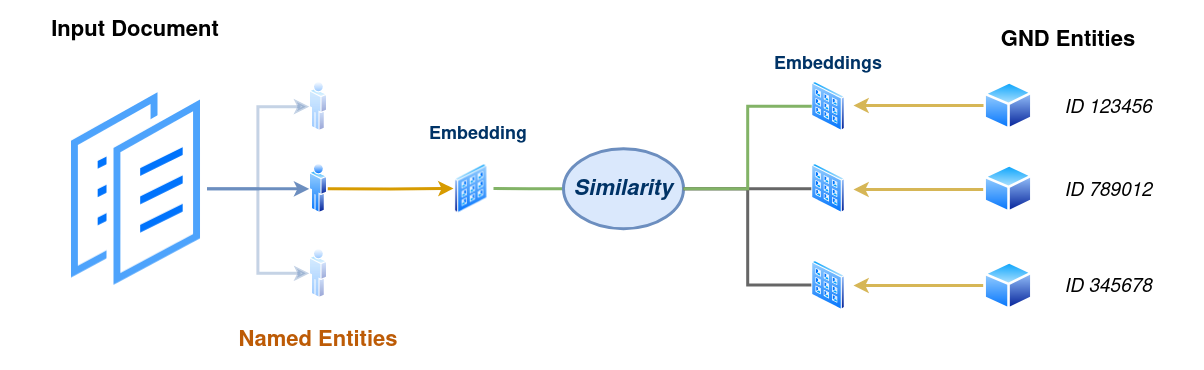
Following this low-threshold approach, Jonas Richter (University of Leipzig) presented his thesis, in which a more advanced approach is tested: a neural model that links entities based on the information contained in the GND (such as place and time data). Additionally, the candidate search, an important step in the overall process that aims to narrow down the initial broad search space, is to be improved compared to a simple string search – here, too, embedding similarities should help identify the most suitable candidates in the knowledge base.
However, the lecture also addressed the application of already annotated datasets. The session concluded with an insight into an extension of the Federated Content Search (FCS), which is being developed at SAW.
As the name suggests, the FCS is a specification and platform for content search across distributed (federated) resources. Many data collections in Text+ are already searchable via the project’s own FCS. The platform is continuously expanded, for example, by adding an entity-based content search, enabling users to find an entity in a corresponding annotated dataset using its GND ID. The lecture ended with a demonstration of the working prototype of this EntityFCS, using data from the previously shown letters and documents on church politics!
The topic clearly interests many researchers and has concrete practical relevance, as evidenced not only by the number of participants but also by the lively question-and-answer sessions and discussions between the contributions. After this lecture, it can be assumed that Entity Linking will remain a key topic within Text+!
Felix Helfer (October 31, 2024). Entity Linking, a Text+ IO-Lecture. Text+ Blog. Retrieved December 20, 2024 from https://doi.org/10.58079/12lp4
GND Forum NFDI, FIDs & Co. on December 10, 2024
An Overview – Cross-Project Insights into Work Around the GND
Although many more people had registered for the GND Forum NFDI, FID & Co. on December 10, 2024, we were very pleased with the 250 attendees who actually participated. The team from the Niedersächsische Staats- und Universitätsbibliothek Göttingen and the Standardization Office of the German National Library, together with the communities of the humanities consortia of the National Research Data Infrastructure (NFDI), the scientific subject-specific information services (FIDs), and other research initiatives, put together a rich program of lectures for the participants.
The GND Forum NFDI, FID & Co. invited all interested parties to learn about current projects related to the Gemeinsame Normdatei (GND) in the German-speaking world. As the event was primarily an informational gathering, the focus of the documentation is on making available the presentation slides from the nine lectures. The presentations covered various aspects of working with the GND from different perspectives and introduced the role of the GND for the different communities. Most of the talks can be described as “workshop reports”, reflecting the diverse content and assumed knowledge of the audience. The ninth talk rounded off the program with a presentation of a pilot application for AI-based content indexing. Below is the complete program.

Dates
All events – both upcoming and past – can also be found in our event calendar on the Text+ portal..
Joint workshop on Large Language Models (LLMs) in publishing
How Will Large Language Models (LLMs) Change the Future of Scientific Publishing? To address this central question, six NFDI consortia are organizing a one-day workshop on “Large Language Models and the Future of Scientific Publishing” on February 11, 2025. The interdisciplinary event will bring together representatives from academia, the publishing industry, and tool developers to discuss the opportunities and challenges presented by the use of LLMs. Participation is free of charge. For registration and more information, visit: https://indico3-jsc.fz-juelich.de/event/202/
| Datum | Event | Ort |
|---|---|---|
| 30 October 2024 | NFDI und Spezialbibliotheken im Gespräch – eine Umfrage des NFDI Konsortiums Text+ zu Katalogdaten von Bibliotheken | virtuell |
| 31 October 2024 | Text+ Research Rendezvous | virtuell |
| 06 November 2024 | IO-Lecture: Migration von RocketChat zu Matrix | virtuell |
| 12 November 2024 | Text+ Research Rendezvous | virtuell |
| 14 November 2024 | Erschließen, Forschen, Analysieren | virtuell |
| 18/19 November 2024 | Digitale Wörterwelten: Einblick in die Text+ Infrastruktur | Berlin |
| 20/21 November 2024 | 1st Base4NFDI User Conference (UC4B2024) | Berlin |
| 27 November 2024 | 5. FID / Text+ Jour Fixe - Verzeichnen und Ablegen | SUB Göttingen |
| 28 November 2024 | Text+ Research Rendezvous | virtuell |
| 04 December 2024 | IO-Lecture: Wie kommt mein Dienst ins Portal? | virtuell |
| 04 December 2024 | Verknüpfung und Kontextualisierung: Die Gemeinsame Normdatei als ein PID-System für Kulturelle Objekte in GLAM-Institutionen | virtuell |
| 10 December 2024 | Text+ Research Rendezvous | virtuell |
| 10 December 2024 | GND-Forum NFDI & Co. | virtuell |