Knoten knüpfen sich nicht von allein – GND-Forum Text+
Dokumentation der Veranstaltung
Lesezeit: 12 Minuten
Die Dokumentation und Auswertung des GND-Forums Text+ richtet sich an die Teilnehmenden der Veranstaltung selbst, die eingeladen sind, mit uns den Austausch und die Arbeit fortzusetzen. Darüberhinaus möchten wir hier alle an Normdaten, insbesondere der GND Interessierten ansprechen, die mit sprach- und textbasierten Forschungsdaten arbeiten. Mit der GND-Agentur Text+ entsteht in den nächsten Monaten ein Unterstützungsangebot, um die eigenen Daten an die GND anzubinden, die GND für die eigene Arbeit zu nutzen oder aber die eigenen Daten für die GND aufzubereiten und anzureichern.
Als ein zentraler Part des Maßnahmenkatalogs von Text+, namentlich von Task Area “Infrastructure and Operations” (TA I/O) ist der Aufbau einer Agentur zur aktiven Mitgestaltung der Gemeinsamen Normdatei (GND). Die GND-Agentur adressiert einerseits die spezifischen Community-Bedarfe der Mitwirkenden von Text+ in den drei Datendomänen und zeigt andererseits möglichst früh dieser Community Möglichkeiten zur aktiven Mitarbeit auf. Das Sammeln der Anforderungen steht dabei natürlich am Anfang der Arbeit. Daher fand am 15. Juni 2022 mit über 60 Teilnehmerinnen und Teilnehmern die Auftaktveranstaltung zum GND-Forum Text+ statt. Das GND-Forum Text+ wird in den kommenden Jahren der zentrale Rahmen sein, um den Austausch und die gemeinsame Entwicklung der GND-Agentur für Text+ mit der Community zu fördern.
Ziel der Veranstaltung war es, den Zielgruppen von Text+ sowie weiteren Beteiligten aus dem Kreis der GND-Anwender*innen in einem offenen Diskussionsraum die Möglichkeit des Austauschs sowie der Formulierung konkreter Bedarfe nach standardisierter Erschließungspraxis und Nutzung der GND zu geben. Die Veranstaltung diente als Auftakt für weitergehende thematische Workshops und der Vernetzung untereinander während der gesamten Projektlaufzeit. Die Mehrheit der Teilnehmer:innen war aus den drei Datendomänen von Text+ sowie der TA I/O, aber auch über Text+ hinaus aus anderen Kreisen, bspw. NFDI4Culture, dabei. Dies zeigen auch die Umfrageergebnisse in der Abbildung 1 und Abbildung 2. Interessanterweise betrachteten sich viele Teilnehmende eher als Manager*in oder Entwickler*in, denn als Forschende. Die Sammler*innen kamen vermutlich aus dem Bereich der Bibliotheken.
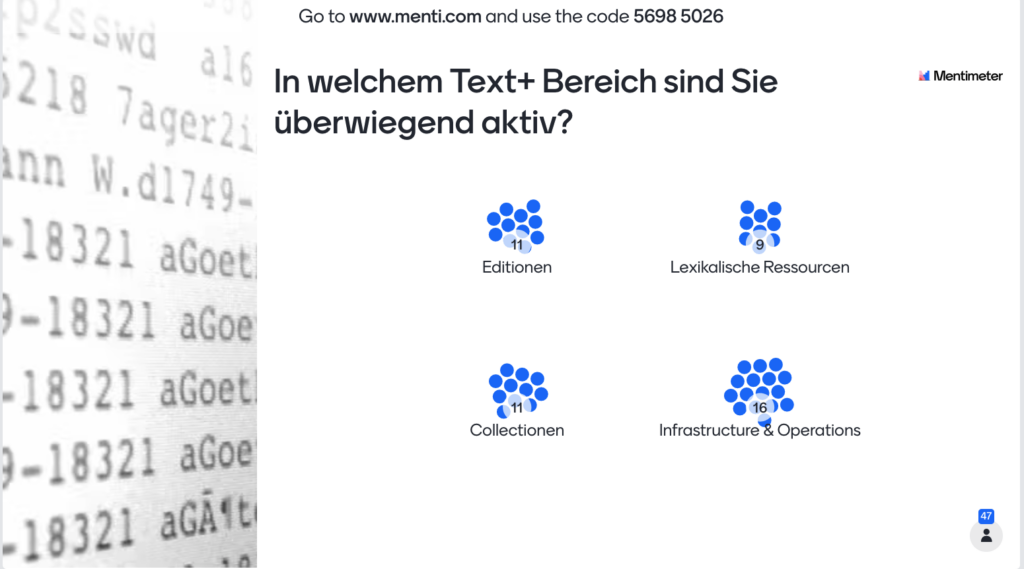
Abb. 1: Umfrageergebnis
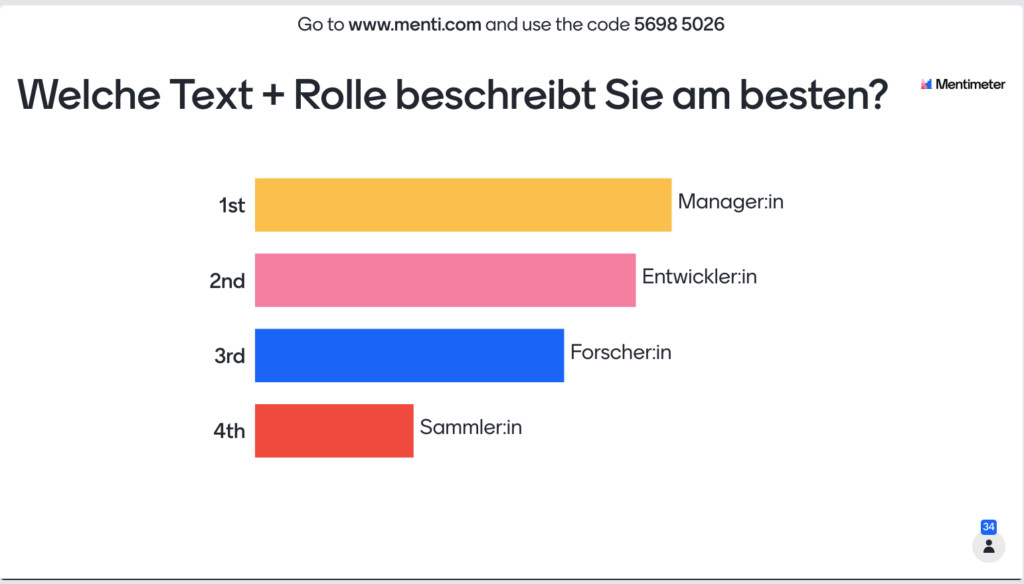
Abb. 2: Umfrageergebnis
In dem Format “Forum” des GND-Netzwerkes wechseln sich Vortragselemente und Gelegenheiten zum intensive Austausch zu spezifischen Fragen ab. Übertragen auf das GND-Forum Text+ waren dies informative Lightning Talks zu konkreten Umsetzungsbeispielen aus den drei Datendomänen von Text+ (Editionen, Sammlungen und Lexikalische Ressourcen) und intensive Diskussionen in Kleingruppen zu den zentralen Fragen zur Rolle der GND in Datendomänen von Text+, um so die konkreten Bedarfe, Anforderungen und offenen Fragen der Text+ Community zu sammeln. Ein Screenshot (siehe Abb. 3) auf das digitale Whiteboard der Veranstaltung verschaunlicht gut die Intensität der Beteiligung aller Teilnehmenden.
Über das Verschränken von Datennetzwerken und Communities
Nach der Begrüßung durch Stefan Buddenbohm (Niedersächsische Staats- und Universitätsbibliothek Göttingen) und Barbara Fischer (Deutsche Nationalbibliothek) informierte Jürgen Kett (Deutsche Nationalbibliothek) in seinem Vortrag zunächst über die Rolle der GND mit den beiden Facetten als Datenset sowie als Brücke innerhalb verschiedener Communities innerhalb und über Text+ hinaus auch vor dem Hintergrund der gesamten NFDI. Einen Schwerpunkt seines Vortrags bildete das Herausstellen der möglichen Nutzenpotenziale für Forschende, die ihre Daten in die GND bringen oder Daten aus der GND nutzen (siehe Abb. 4).
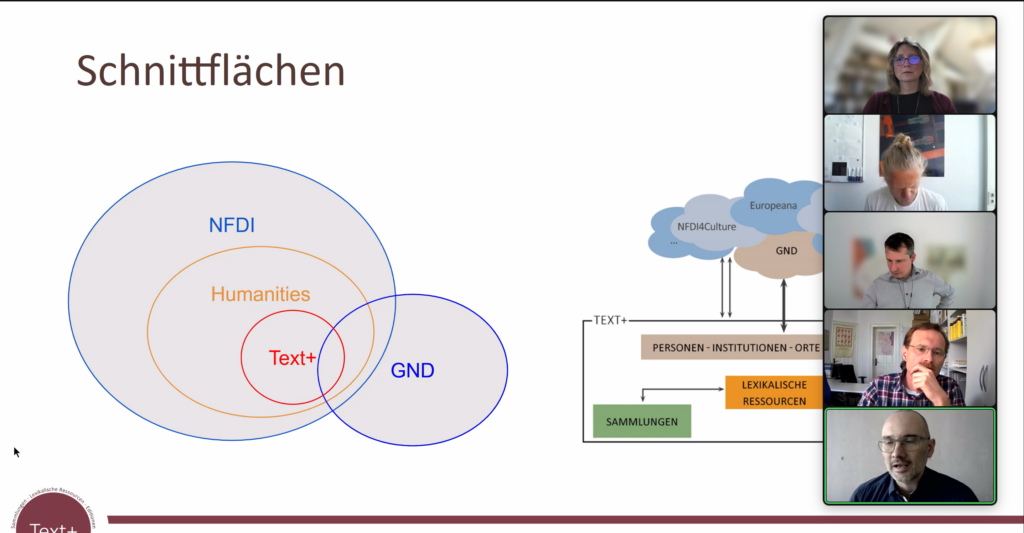
Abb. 4: Screenshot aus dem Vortrag von Jürgen Kett (DNB), Juni 2022
Die GND als Datenset umfasst aktuell rund 10 Mio. Entitäten unterschiedlicher Typen, wobei Personen zurzeit den größten Teil ausmachen, gefolgt von Körperschaften und Kongressen als so genannte Ereignisdaten, Werken, Geografika und Sachbegriffen. Die GND ist dabei keine abgeschlossene Liste, der jährliche Zuwachs variiert in Abhängigkeit von entsprechenden Projekten. Generell gilt für die einzelnen Entitäten, dass jeweils abzuwägen ist, ob eine Aufnahme in die GND sinnvoll erscheint, insbesondere um Redundanzen zu bereits vorhandenen Verzeichnissen zu vermeiden.
In der Funktion als Brücke bzw. Datennetzwerk verbindet die GND derzeit hauptsächlich Sammlungen und Bestände aus dem Bereich der Bibliotheken, Archive und Museen, aber zunehmend auch Forschungsdaten in Form von beispielsweise Fachdatenbanken oder Editionsprojekten. Ein anderer Teil des Netzwerks bezieht sich auf Mappings zu Wissenssystemen, internationalen Normdateien und eng mit der GND verwobenen Fach-Thesauri.
Die Antwort auf die Frage, welche Daten für die GND geeignet sind, leitet sich aus dem Bedarf der jeweiligen Fachcommunity ab und was diese für die Vernetzung ihrer Daten benötigt. Hier existiert eine Art Selbstregulation, da mit dem Einspeisen in die GND eine dauerhafte Verpflichtung verbunden ist, die i.d.R. auch nur für als relevant befundene Daten eingegangen wird.
Tweet zum Vortrag von Jürgen Kett (DNB)Die GND kann lässt sich mit einem gemeinsamen Haus (siehe Abb. 5) vergleichen, in dem auf verschiedenen Ebenen Abstimmungen über Regelwerke und Datenmodelle sowie das praktische Arbeiten über Agenturen, Redaktionen und Anwender*innen erfolgen. Konkretes Ziel im Rahmen von Text+ ist der Aufbau einer GDN-Agentur für sprach- und textbasierte Forschungsdaten, um die GND-Datenbasis zu erweitern und einfache Dienste zur Meldung, Pflege und Mappings bereit zu stellen. All diese Dienste müssen über entsprechende Schnittstellen auch in die Gesamtinfrastruktur der NFDI integriert werden.
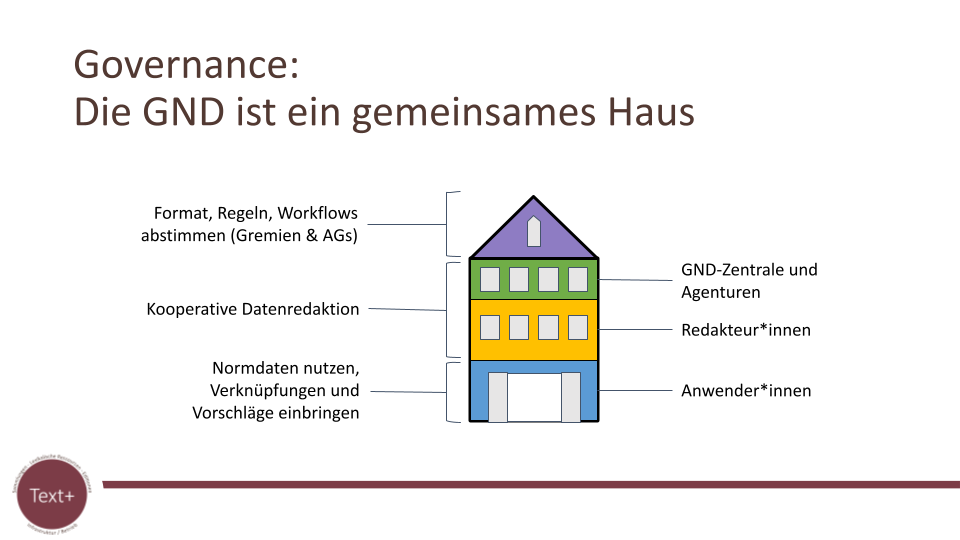
Abb. 5 : Die GND ist ein gemeinsames Haus (credit: Jürgen Kett (DNB), June 2022, CC BY SA
Tweet zum Vortrag von Jürgen Kett (DNB)
Mitschnitt des Vortrags von Jürgen KettVortragsfolien (PDF): Jürgen Kett: GND x NFDI: Über das Verschränken von Datennetzwerken und Communities
Die GND in der Anwendung am Beispiel von Editionsprojekten
Im ersten Lightning Talk stellten Harald Lordick (Ludwig Salomon Steinheim Institut für deutsch-jüdische Geschichte) und Uwe Sikora (Niedersächsische Staats- und Universitätsbibliothek Göttingen) Anwendungsbeispiele aus der Text+-Datendomäne Editionen vor.
Bei der Aufbereitung digitaler Editionen liegt ein Schwerpunkt auf der eindeutigen Identifikation der in den Texten vorkommenden Entitäten, wobei der Hauptakzent derzeit auf Personen liegt. Des Weiteren werden aber auch Körperschaften, Geografika oder Werke durch Normdaten ausgezeichnet. In der Praxis hat sich hierfür der de-facto Standard TEI etabliert, wobei die Auszeichnung direkt, indirekt oder durch die Nutzung von Surrogat-Formaten erfolgen kann (siehe Abb. 6). Durch die auf diese Weise annotierten Editionen sowie durch die Erstellung von BEACON-Dateien ergeben sich in der Folge vielfältige Verwendungsmöglichkeiten für die Nachnutzung, die Aufnahme in Register oder den Aufbau von Personennetzwerken, und somit neue Forschungsfragen und -antworten. Neben der Vernetzung mit der Außenwelt besteht ein weiterer Vorteil in der Anreicherung der eigenen Daten mit externen Informationen, auf die über einen entsprechenden zentralen Service zugegriffen werden kann. Schließlich erhöht die Annotation auch die FAIRness und damit die Datenqualität. Abschließend lässt sich folgern, dass nicht Tiefe, sondern vor allem Quantität an GND-Entitäten entscheidend sein wird, und die Möglichkeit aktiv in der GND mitzuwirken, unterstrich Harald Lordick in seinem Beitrag (siehe Tweet).

Abb. 6: Surrogat-Formate zur Entitätenauszeichnung als einer von vier Wegen (Uwe Sikora (SUB), Juni 2022, CC BY SA)
Tweet zum Beitrag von Harald Lordick (SI)
Notizen aus der Fragenrunde:
- Philipp Hegel (TU Darmstadt): Wie geht man bei der Auszeichnung mit Unsicherheiten um?
- Matthäus Heil (BBAW): Gleiche Frage. In manchen Bereichen sind viele Identifikationen Gegenstand von Forschungskontroversen.
- Antwort von Uwe Sikora (SUB Göttingen): Man kann nur dokumentieren, wie man versucht hat zu identifizieren und den Evaluierungsmechanismus bewerten. Das muss jedes Projekt für sich selbst bewerkstelligen.
Mitschnitt des Vortrags von Uwe Sikora & Harald Lordick
Vortragsfolien (PDF): Harald Lordick, Uwe Sikora: Die GND in der Anwendung am Beispiel ausgewählter Editionsprojekte und Vernetzungspotenziale und -initiativen
Wozu Normdaten? Welche grundsätzlichen Nutzenpotenziale ermöglichen sie?
Break Out Session 1
An den Vortrag schloss sich die erste Break Out Session an, in der zum Einstieg die Frage vertieft wurde, welche Vorteile in der Text+ Community durch die Nutzung der Normdaten der GND herausgestellt werden und welche weiteren Nutzenpotenziale sie ermöglichen. Vorteile, die für die Anwendung von Normdaten sprechen, kristallisierten sich vor allem unter den Schlagworten
- Eindeutigkeit
- Vernetzung
- Sichtbarkeit
- Arbeitserleichterung
- Qualitätssteigerung
Im Einzelnen können die Impulse auf dem Conceptboard nachgelesen werden. An dieser Stelle ein Screenshot aus dem Kategorisierungsprozess (Abb. 7).
Abb. 7: Cluster aus der Session 1 zur Frage “Warum?”
Das Potential der GND für sorbische Sprachressourcen
Im zweiten Lightning Talk von Hauke Bartels und Marcin Szczepański (beide Sorbisches Institut) stand die Datendomäne Lexikalische Ressourcen im Vordergrund und zeigte das Potenzial der GND am Anwendungsfall für sorbische Sprachressourcen auf. Die Zusammenarbeit mit dem Sorbisches Institut ist für Text+ von besonderem Interesse vor dem Hintergrund dessen, dass mit der Forschung zu sorbischen Sprachressourcen nicht nur der Aspekt der Mehrsprachigkeit diskutiert werden kann, sondern auch die Spezifik kleiner Sprachen. Im Falle des Nieder- und Obersorbischen kommt zusätzlich die Eigenschaft als Amtssprachen zur Geltung. Ziel des Projektes ist die Weiterentwicklung der internen sowie externen Vernetzung unter Heranziehung der GND. In den untersuchten Ressourcen werden Elemente ihrem Vernetzungspotential entsprechend zunächst in verschiedene Gruppen eingeteilt, wobei vier Typen erkennbar sind, bei denen eine Vernetzung als (1) gar nicht, (2) theoretisch möglich, aber sehr spezifisch und anspruchsvoll, (3) nur teilweise für gewisse Datenaspekte (siehe Abb. 8) bzw. (4) in voller Ausnutzung als sinnvoll erachtet werden. Personen und Orte bieten sich besonders zur Vernetzung an. Aktuelle Arbeiten erfolgen an einem Namensservice, der sorbische Personen- und Ortsnamen mit Wörterbüchern, aber auch mit Datenbanken wie Wikidata und der GND verbindet.

Abb. 8: Aus dem Vortrag von Marcin Szczepański (Sorbisches Institut, Juni 2022, CC BY SA)
Geplant ist weiterhin die umfassende Aufbereitung eines historischen Vollkorpus (ausgehend vom 16. Jh. bis zur Gegenwart) mit niedrigschwelligem Zugang zum gesamten niedersorbischen Schrifttum und die Konzeption eines Registers. Dabei sollen sämtliche in den Texten vorkommende Eigennamen als Teil des sorbischen Kulturerbes annotiert werden. Eine besondere Herausforderung stellen hierbei die Namensvarianten und die Mehrsprachigkeit dar. Teilweise sind Namensvarianten in der GND bereits vorhanden. Für dieses Projekt ist ein koordiniertes Vorgehen in Zusammenarbeit mit der GND erforderlich, um abzugrenzen, welche Datensätze weiterhin in internen Wörterbüchern vorgehalten werden und welche direkt in die GND einfließen sollten.
Abb. 9: Aus dem Vortrag von Hauke Bartels (Sorbisches Institut, Juni 2022, CC BY SA)
Mitschnitt des Vortrags von Hauke Bartels und Marcin Szczepański
Vortragsfolien (PDF): H_a_uke Bartels & Marcin Szczepański: Das Potenzial der GND für sorbische Sprachressourcen. Eigennamen als Datenbestand und Schlüssel zu Texten
Um welche konkreten Bedarfe geht es?
Break Out Session 2
In der anschließenden zweiten Break Out Session gab es Gelegenheit zur Diskussion zu der Frage, welche konkreten Bedarfe an die GND existieren. Der Anforderungskatalog erstreckt sich dabei von Wünschen an die enthaltenen Daten und Datenmodelle bis hin zu zusätzlichen Features und Werkzeugen zur Vernetzung, zum Qualitätsmanagement und zur Mehrsprachigkeit.
Im Einzelnen können die Impulse auf dem Conceptboard nachgelesen werden. An dieser Stelle ein Screenshot aus dem Kategorisierungsprozess (Abb. 10).
Abb. 10: Cluster zur Session 2 “Was?”
Korpora und Normdaten
Der dritte und abschließende Lightning Talk von José Calvo Tello (Niedersächsische Staats- und Universitätsbibliothek Göttingen) lenkte den Blick auf die Text+-Datendomäne Sammlungen und zeigte Vorteile und Herausforderungen bei der Verwendung von Normdaten in literaturwissenschaftlichen Korpora auf. Bei der Zusammenstellung von Korpora werden in der Literaturwissenschaft in der Hauptsache zwei Entitätentypen berücksichtigt: (1) Personen mit Angaben zu Geburtsdaten (wie Jahr, Ort und Staatsangehörigkeit) sowie zum Geschlecht und (2) Werke als Erstausgabe mit Angaben zur Originalsprache, zum Veröffentlichungsjahr sowie zur Gattung, aber auch zu Körperschaften wie Verlage oder zu literarischen Preisen.
Tweet zum Vortrag von José Calvo Tello (SUB)
Die Verknüpfung mit anderen Ressourcen durch die Nutzung von Normdaten wurde als eindeutiger Vorteil herausgestellt. Weiterhin sind normierte Daten automatisch aufgeräumter, was den Vergleich zu anderen Korpora erleichtert. Auch die Extraktion einer Untermenge gelingt mit strukturierten Daten leichter. Darüber hinaus können durch die Verknüpfung mit Normdaten sehr leicht weitere qualitative Daten für die Analyse gewonnen werden. Dies konnte durch die Auswertung von aus Wikidata gewonnenen Daten zu Geburts- und Todesort bestimmter Autoren visuell eindrucksvoll demonstriert werden (siehe Abb. 11).
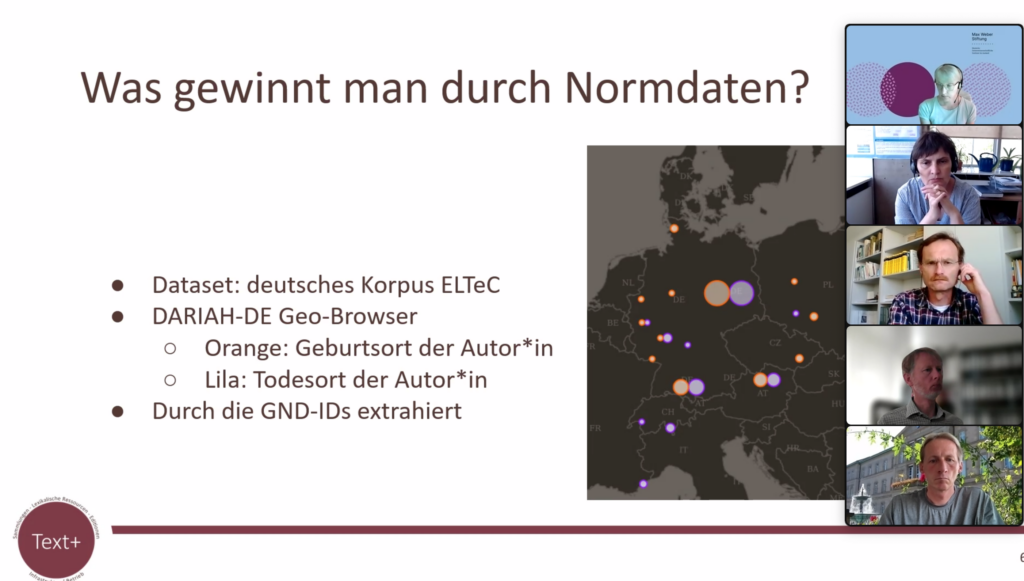
Abb. 11: Aus dem Vortrag von José Calvo Tello (SUB)
Eine Herausforderung besteht in der Lücke hinsichtlich fremdsprachlicher Instanzen in der GND. Schließlich wurde auch der Frage nachgegangen, wie ein einzelner Forscher bei der GND mitwirken kann. Dies kann zum einen durch das Hinzufügen von Daten in Form neuer Entitäten zu Personen und Werken, die noch nicht in der GND vorhanden sind, erfolgen, zum anderen aber auch durch neue Informationen zu Personen und Werken, die bereits in der GND enthalten sind. Hier stellt sich die Frage, wie die Kommunikation zwischen der GND und der Wissenschaft fungiert.
Mitschnitt des Vortrags von José Calvo Tello
Vortragsfolien (PDF): José Calvo Tello: Literaturwissenschaft, Korpora und Normdaten: Vorteile und Herausforderungen
Notizen aus der Fragenrunde:
- Julijana Nadj-Guttandin (DNB): Die Frage „Was kann ein Forscher zum GND-Datensatz beitragen“ führt zu der Diskussion, ob wir auf Ebene des GND-Datensatzes Inhaltserschließung betreiben wollen. Aus bibliothekarischer Sicht ist das nicht relevant, weil es nicht zur eindeutigen Erschließung einer Ressource beiträgt.
- Antwort Jürgen Kett (DNB): Bei der Inhaltserschließung am Werksatz muss differenziert werden, wie tief und wie wissenschaftlich diese gehen darf.
- Antwort José Calvo Tello (SUB Göttingen): Die Information Gattung gehört eher zur Werkebene und nicht zur Titelebene. Diese Information ist in den Katalogdaten nicht vorhanden, spielt aber in den Forschungsarbeiten eine zentrale Rolle.
- Nachfrage Gerrit Brüning (Uni Frankfurt): Keine Inhaltserschließung in der GND? Vgl. den Datensatz zu Goethes Erlkönig: https://d-nb.info/gnd/4424800-3
Hier findet unter „Weitere Angaben“ doch Inhaltserschließung statt, wo man diese Information nicht erwarten würde. Ist das sinnvoll?
- Uwe Sikora (SUB Göttingen): Wo ist das Genre eines Textes anzusiedeln? Unter Eigenschaften des Werks? Alle Daten, die man angibt, dienen der Beschreibung und detaillierteren Anreicherung. Ein Wunsch wäre, „Weitere Angaben“ hier herauszunehmen und dafür ein eigenes Datenfeld anzulegen, das man abfragen kann.
- Antwort Julijana Nadj-Guttandin: Die Frage nach der Inhaltserschließung am Werk ist nicht abschließend geklärt. Oberstes Primat in der GND ist aber sicherlich die eindeutige Identifikation. Partikulare Interessen können mit abgefangen werden. Das Datenformat kann auch noch weiter differenziert werden.
Was und wie kann ich als Forschende/r beitragen? Welche Unterstützung benötige ich?
Break Out Session 3
Der letzte Vortrag leitete thematisch über zur letzten Break Out Session, in der die zentrale Kernfrage behandelt wurde, was und wie Forschende zum Ausbau der GND beitragen können und welche Unterstützung sie dazu benötigen. Hier teilen sich die Antworten auf die drei Kategorien Informationen, Dienste und Werkzeuge. Im Einzelnen können die Impulse auf dem Conceptboard nachgelesen werden. An dieser Stelle ein Screenshot aus dem Kategorisierungsprozess (Abb. 12).
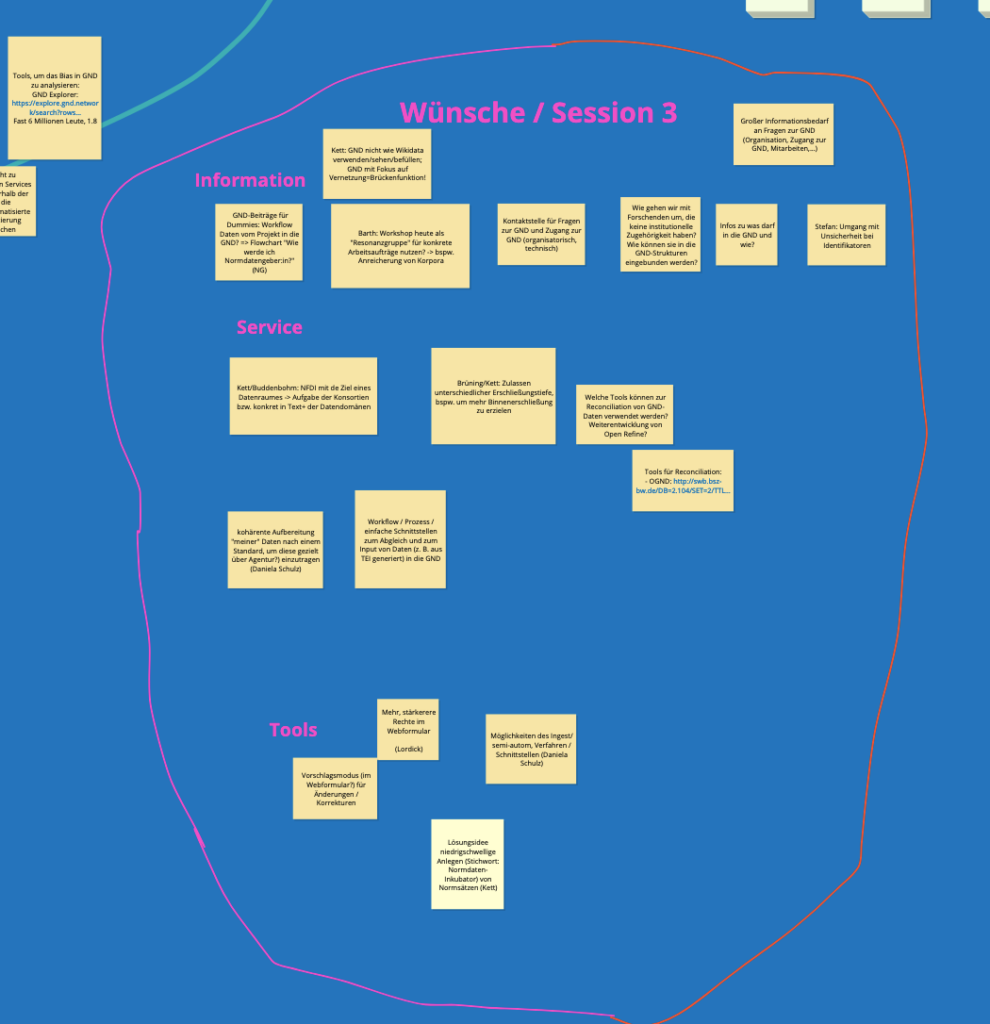
Abb. 12: Cluster zur Session 3 “Wie?”
Aspekte aus der Abschlussdiskussion
In der Abschlussdiskussion wurden die in den einzelnen Breakout-Sessions gesammelten Notizen unter verschiedenen Kategorien gebündelt dem gesamten Auditorium zur gemeinsamen Auswertung vorgestellt. In der anschließenden Diskussion kristallisierten sich sechs Ideen heraus, die als Fragestellungen oder eine Art Fallstudien auch Domänen übergreifend weiterverfolgt werden sollen. Diese waren in chronologischer Reihenfolge ihres Auftretens in der Diskussion:
- Sichtbarkeit der eigenen Daten: Entwicklung von Verfahren anhand von ausgewählten Beispiel, welche die GND-annotierten Forschungsdaten für andere sichtbarer machen
- Erweiterung der GND: Eine Basis für Vorschläge für neue Datensätze und Entwicklung dazu notwendiger Workflows und Austauschformate schaffen.
- Definition von Grenzen: Wo endet der eigene Forschungssatz bzw. wo beginnt die GND? Welche Werkzeuge / automatisierte Prozesse können für den Abgleich herangezogen werden?
- Mehrsprachigkeit: Welche neuen Anforderungen bestehen an das Datenmodell / Welche Regeln gibt es seitens der GND hierzu bereits?
- Referenzimplementation (Domain Collections Registry) Kenntlich machen, ob GND-Daten referenziert wurden und Metadaten zu den Collections mit GND anreichern
- Mappings erstellen und teilen (welche Allgemeinbegriffe verwendet man im Forschungstext respektive GND & darüber informieren)
Wir, d.h. das GND-Team in IO, werden in den kommenden Wochen zu diesen Themen zu weiteren Treffen einladen, damit sich aus den Ideen konkrete Casestudies herausschälen können, die uns allen gemeinsam helfen werden, eine GND-Agentur möglichst nah an den Bedarfen und Möglichkeiten der Text+ Community zu gestalten. Das Forum hat einen Auftakt zum intensiven Austausch mit den Text+ Datendomänen gebildet, auf dem es nun aufzubauen gilt.
Über die oben genannten sechs geclusterten Ideen gab es eine Vielzahl weiter Beiträge. Teilweise sehr spezifische Fragen oder Anregungen, teilweise auch bereits über Text+ hinausreichend und die NFDI als Ganzes in den Blick nehmend. Eine Auswahl:
- Forschung zu sorbischen Sprachen (Obersorbisch, Niedersorbisch) als interessanter Aspekt in Text+ und der NFDI insgesamt, da es hier nicht lediglich um Mehrsprachigkeitsaspekte geht, sondern um Minderheitensprachen im Range einer Amtssprache. Text+ könnte diesem Aspekt innerhalb der NFDI Geltung verschaffen und hat unter der Überschrift Normdaten/GND konkrete Umsetzungs- oder Pilotideen an der Hand, die idealerweile ausstrahlen oder sich auf andere Szenarien übertragen lassen.
- Fokus auf Use Cases/ Demonstratoren/ Anwendungen, die auf einfache Art und Weise den Nutzen von Normdaten und der GND im Kontext von Text+ veranschaulichen. Dies könnte bspw. ein Walkthrough mit dem GND-Explorer durch die Text+ Datendomänen (“Stöbern mit dem GND-Explorer”) sein oder kurze Beschreibungen im Stile der Text+ User Stories, die von konkreten Forschungsvorhaben ausgehen und so eine Brücke zur Community schlagen.
- Fokus auf die Datendomäne Lexikalische Ressourcen, insbesondere GermaNet. In GermaNet verzeichnete Ortsnamen sind bisher noch nicht mit Normdaten versehen. Eine weitere, potenziell interessante lexikalische Ressource wäre das Digitale Wörterbuch der Deutschen Sprache der BBAW, bei dem die GND-Anbindung unter Berücksichtigung bereits vorhandener Erschließung in Wikidata umgesetzt werden könnte.
- Den Aufbau der GND-Agentur Text+ mit den anderen Agenturen und NFDI-Konsortien abstimmen bzw. in einen intensiven Austausch miteinander treten, um voneinander zu lernen (Best Practices) und idealerweise Synergien zu heben. Insbesondere in der Ansprache der Communities erscheint es sinnvoll, bestimmte Aktivitäten zu bündeln.
Auswertung: Ergebnisse der Veranstaltung und Schlussfolgerungen
Lesezeit: 3 Minuten
Die Auftaktveranstaltung des GND-Forums Text+ diente dem Sammeln von Anforderungen für den Aufbau einer GND-Agentur nach den Bedarfen der Text+ Community. Dies ist eine wichtige Aufgabe von Text+, namentlich in der Task Area “Infrastructure and Operations” (TA I/O). Es gilt, einerseits die spezifischen Community-Bedarfe der Mitwirkenden von Text+ in den drei Datendomänen zu adressieren und andererseits möglichst früh dieser Community Möglichkeiten zur aktiven Mitarbeit aufzuzeigen. Die Aufgabe ist Teil der Measure 3 im Text+ Vorhaben. Im zweiten Teil des Berichtes werden die gesammelten Impulse aus der Text+ Community auf die bisherige Arbeitsplanung von TA I/O gespiegelt. Als Fazit der Veranstaltung stellen wir fest: Die zu Beginn des Vorhabens zur Einrichtung einer GND-Agentur antizipierten Anforderungen an Information, Services, Daten, Datenmodell, Tools und Features werden durch die im Forum notierten Impulse verfiziert.
Die Spiegelung trägt dazu bei, die Planung anhand des konkreten Bedarfs auszurichten und vor allem die Mitwirkenden von Text+ unmittelbar in den Entwicklungsprozess der GND-Agentur zu integrieren. In unserer Planung haben wir drei Tätigkeitsbereiche im Vorfeld der Forum-Veranstaltung definiert:
Anhand der GND Arbeit in den Referenzimplemantationen (M1) der Datendomain “Editions” erfassen wir exemplarisch Anforderungen, schaffen in konkreten Fallstudien (Case studies) realistische Testumgebungen, entwickeln und testen prototypische Geschäftsgänge, um schließlich mit der GND-Agentur produktiv gehen zu können.
Der zweite Bereich umfasst Maßnahmen wie die (Weiter)-Entwicklung von Tools und technischer Infrastruktur, die die Partizipation für alle vereinfachen sollen. Beispiele dafür sind der GND-Explorer oder das Wikibase-Projekt an der DNB.
Die beiden Arbeitsbereiche begleiten wir durch eine intensive Community-Arbeit. Ziel ist es hier, zielgruppengerecht zu informieren, eine Community als Gemeinschaft zu formen, Trainingsangebote zu machen, und entsprechende Formate für den Austausch zu entwickeln. Nur im engen Austausch aller an der Text+ Community Beteiligten können wir sicherstellen, dass die Angebote für technische und organisatorische Infrastruktur, die Informations und Trainingsangebote auch wirklich passen.
Die Impulse des Forums
Noch in der Veranstaltung selbst haben wir die Impulse – Wünsche, Anmerkungen, Fragen und Anregungen der Teilnehmenden – aus den drei Break Out Sessions geclustert. Diese Cluster bilden die Community-spezifischen Anforderungen an die Aufgabe in M3 gut ab. Daher konnten wir für die Auswertung die Impulse mit unserer bisherigen Planung gut abgleichen. Wir konnten feststellen, dass sich die bisherige Planung geeigneter Maßnahmen für die Ausformung der GND-Agentur sowie dem Aufbau der Text+ Community rund um diese Agentur mit denen im Forum präsentierten Impulsen weitestgehend deckt.
Zur Sichtung der Impulse im Einzelnen bitte auf das Conceptboard wechseln.
Schlussfolgerungen
Die gesammelten Impulse wirken sowohl auf den Community-Prozess, auf die Maßnahmen zur Agenturentwicklung und zum Teil auch auf die Planungen im Bereich der technischen Infrastruktuangebote ein. In den nachfolgenden “Lessons learned” fassen wir die Schlussfolgerungen für unsere Projektarbeit zusammen und illustrieren anhand von Beispielen, wie wir daraus konkrete Maßnahmen und Produkte in Zusammenarbeit mit der Text+ Community entwickeln möchten.
- Vor allem zu den für die Text+ Community als relevant genannten Vorteile der GND werden wir entsprechende Materialien und Handreichungen für Text+ entwickeln und die bezeichneten Informations-/Service-Bedarfe adressieren (Siehe Dokumentation Session 1). Das kann zum Beispiel ein Produkt wie eine Handreichung zur Qualitätssicherung in der GND sein, oder Material welche Anforderungen an die Datentiefe gelten oder darüber informieren auf welche Geschäftsgänge Mitglieder der Text+ Community wie zugreifen können.
- Bei der Entwicklung von Tools und Anwendungen an der DNB und im Text+ Konsortium selbst werden wir auf die im Forum zur Sprache gebrachten Bedarfe achten (Siehe Dokumentation Session 2). Bei der Weiterentwicklung von Tools wie dem GND Explorer oder der Neuentwicklung von Anwendungen wie einem Normdaten - Inkubator können jetzt die geäußerten Bedarfe bei der Entwicklung berücksichtigt werden. Möglicherweise werden wir zu einigen Tools auch gezielt Treffen veranstalten, um iterativ die Entwicklung bedarfsgerecht vorantreiben zu können.
- Im weiteren Projektverlauf werden sich die vorhandenen Gremienstrukturen für die Diskussion von Bedarfen zu Daten und Datenmodell für die Text+ Community öffnen. Um die Wünsche und Fragen unter “Daten” und “Datenmodell” (Siehe Dokumentation Session 3) besser adressieren zu können, werden wir einerseits die Gremienstruktur der GND der Community erläutern und andererseits dafür werben, sich in geeigneter Weise in diese einzubringen. Workshops wie das Forum fungieren hier als Vorfeld der verbindlicheren Mitarbeit in Gremien.
- Aus den gesammelten Ideen können wir weitere Casestudies entwickeln, die die Nutzung der GND durch die Text+ Community erweitern und verbessern helfen (Siehe Dokumentation der Abschlussdiskussion). Die zu konkretisierenden Ideen verdichten wir in den folgenen Monaten hinsichtlich ihrer Relevanz für die Text+ Community und ihre Umsetzbarkeit. Hierzu werden wir direkt zur Beteiligung aufrufen.
Nächste Schritte
In den kommenden Wochen und Monaten werden wir auf Sie, die Teilnehmenden des GND-Forum Text+, zugehen und Sie einladen beispielsweise an der Ausformung der oben genannten Ideen mitzuwirken, um sie zu konkretisieren oder auch, um vertieftes Feedback zu den gelisteten Ideen für Features und Tools zu gewinnen. Dazu werden wir Arbeitskreise einrichten und Workshops anbieten, zu denen Sie herzlich eingeladen sind. Gleichzeitig können wir aus den gesammelten Impulsen bereits konkrete Ideen für Produkte ableiten, die wir Ihnen dann vorstellen werden.
Bleiben Sie am Ball, bringen Sie sich aktiv in den Workshops und Arbeitskreisen ein, nutzen Sie den Helpdesk und die Mailingliste sowie unsere Kontaktdaten, um mit Ihren Fragen und Beiträgen die Umsetzung des Vorhabens, die GND für Ihre Forschungsdaten nutzbarer zu machen, aktiv zu gestalten und zu unterstützen. Denn Knoten knüpfen sich nicht von allein.
Ankündigungstext
Die GND für die Text+ Community nutzbarer machen
Wie können die Normdaten für die Forschung in den Text- und Sprachwissenschaften konkret anwendbarer gemacht werden? Wie lassen sie sich durch andere kontrollierte Vokabulare ergänzen (und durch welche)? Was sind die besonderen Anforderungen und Potenziale in diesem Bereich? Wie können die Bedarfe der Text+ Community bei der Bildung von Normdaten besser Berücksichtigung finden? Und vor allem, wer kann Normdaten anlegen, korrigieren und ergänzen? Diesen Fragen unter weiteren widmet sich das GND-Forum Text+. Wir werden nicht alle Antworten sofort finden, daher versteht sich das Forum als ein Diskussionsraum, der für den gesamten Förderzeitraum von Text+ Menschen aus der Text+ Community offen stehen wird.
Auf dieser informativen und interaktiven Online-Veranstaltung werden Sie Gelegenheit haben, sich zu informieren, aber auch Ihre Fragen zu stellen sowie Ihre Ideen und Ansichten im Kreis der Text+Community zu diskutieren. Wir planen einen bunten Wechsel von spontanen Meinungsbildern, Vorträgen zu den Perspektiven der drei Datendomänen von Text+ (Editions, Collections, Lexical Resources). In Kleingruppen möchten mit Ihnen in den intensiven Diskurs zu den zentralen Fragen vor dem Hintergrund der Vorträge treten. Am Ende tragen wir gemeinsam die Ergebnisse im Plenum zusammen und können vermutlich schon einen Ausblick auf die kommenden Aktivitäten des Forums geben. Das Forum ist von uns als ein dialogisches Instrument der Community gedacht, d.h. wir freuen uns über Ihre Beiträge oder Ideen zur Gestaltung des Dialogs miteinander.
Hier eine Skizze des Programms:
Begrüßung und Who-is-in-madness
Kleine Einführung in den dualen Charakter der GND als Normdatei und als Organisation
Drei Vorträge alternierend mit Break-out session in Kleingruppen zu zentralen Fragen
Die GND in der Anwendung am Beispiel von Editionsprojekten an der Niedersächsischen Staats- und Universitätsbibliothek Göttingen und des Steinheim-Instituts (Text+ Task Area Editions)
Welche Rolle spielt die GND für die lexikalische Erschließung des Sorbischen (Text+ Task Area Lexical Resources)? (angefragt)
Wie können textbasierte Sammlungen (Text+ Task Area Collections) von der GND profitieren? (angefragt)
Gemeinsame Auswertung der Ergebnisse
Wrap up
Veranstalter sind die DNB und die SUB Göttingen für das NFDI-Konsortium Text+.
Hier geht es zur Anmeldung und zum Programmlast modified: Sep 28, 2023