Application Examples
The research initiatives from the text and language sciences described below successfully use standards recommended by Text+ and standards-based tools. A series of workshops will also be offered in the first half of 2025, where these application examples will be presented and discussed. Links to the events will be provided on this page in due course.
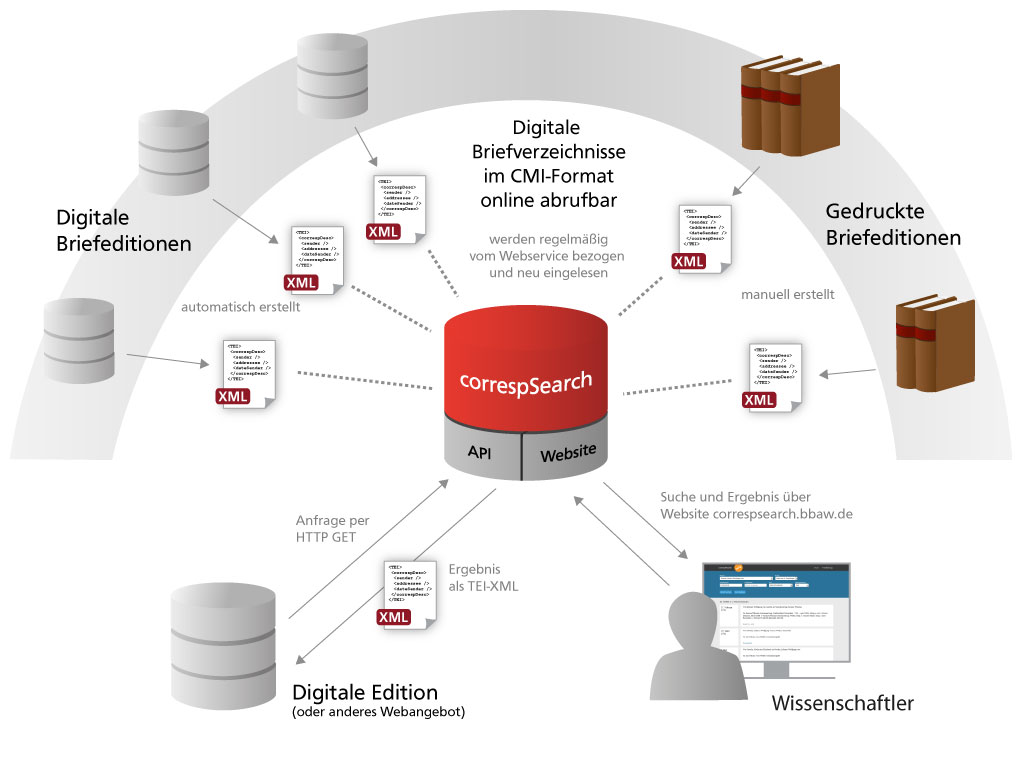
correspSearch – Searching and Connecting Correspondence Editions
The “correspSearch” web service of the Berlin-Brandenburg Academy of Sciences and Humanities (BBAW) aggregates metadata from letters across distributed editions and repositories and provides it centrally through open interfaces under a free license. This allows users to search various digital and printed letter directories by sender, recipient, place of writing, and date.
The foundation of the “correspSearch” web service are digital letter directories provided online in the Correspondence Metadata Interchange (CMI) format. The CMI format is largely based on the “correspDesc” (Correspondence Description) extension for the Text Encoding Initiative (TEI) guidelines. The correspDesc element was developed by the TEI Correspondence SIG to record the correspondence-specific metadata of letters, postcards, etc., in TEI-based editions.
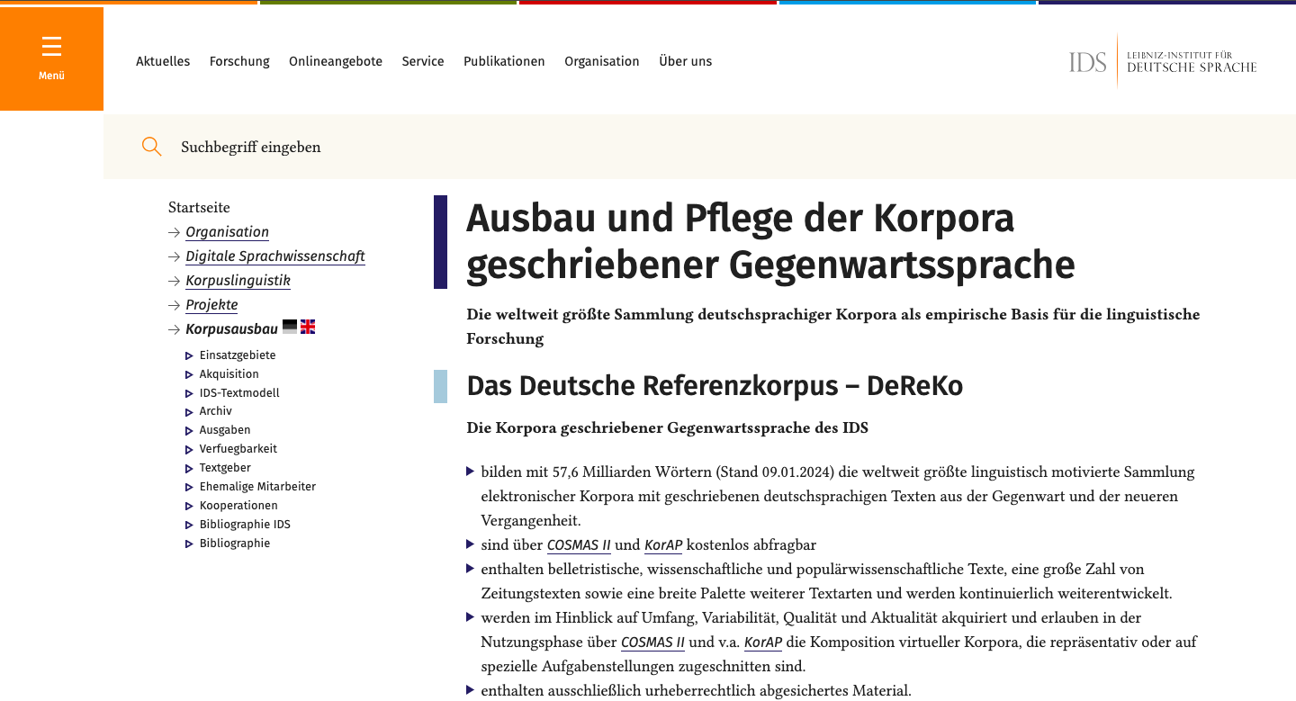
The German Reference Corpus (DeReKo)
The written contemporary language corpora of the Leibniz Institute for the German Language (IDS) constitute the world’s largest linguistically motivated collection of electronic corpora containing written German texts from the present and recent past. They include literary, academic, and popular science texts, a large number of newspaper articles, and a broad range of other text types.
For efficient automatic analysis of large electronic text collections, the texts must be encoded in a unified data structure format. For written language corpora at IDS, this format is the so-called IDS Text Model, based on TEI (Text Encoding Initiative).
German Text Archive (DTA)
The German Text Archive (DTA) of the Berlin-Brandenburg Academy of Sciences and Humanities (BBAW) provides a cross-disciplinary and genre-spanning selection of German-language texts with a publication focus from around 1600 to 1900 as a linguistically annotated full-text corpus.
The DTA places great emphasis on very high accuracy in data capture, structural and linguistic annotation of text data, and the reliability of metadata. A key tool in the development of the corpus was the establishment of a standardized format, the DTA Base Format (DTABf), based on TEI (Text Encoding Initiative). The DTA Base Format is recommended by the DFG for reuse.
The Beria-Collection
The Beria Collection comprises a selection of 12 texts from the Beria corpus. Beria – also known in literature under the exonym Zaghawa – is a language spoken in Darfur, in the border region between Sudan and Chad (Nilo-Saharan, 315,000 speakers). The selected texts were written by two adult men who speak the Sudanese dialect Wagi. They are available digitally in audio-video format in the Cologne Language Archive (LAC, link to online access will follow after publication) and will be fully transcribed, translated, time-aligned and annotated with detailed linguistic information in the form of interlinear glosses as part of the project.
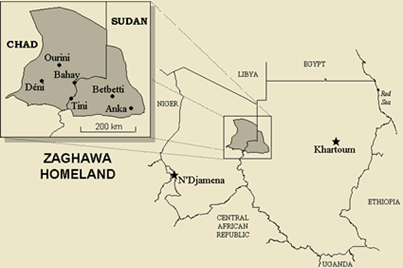
The aim is to integrate a machine-readable and searchable text corpus from an oral, non-European and little-described culture into the Text+ portfolio. A digital lexicon is currently being created in an upstream additional step, which will supplement the text corpus. Standards of general linguistics, as formulated for language documentation corpora by the QUEST guidelines, are being used, including linguistic annotations in IPA and in accordance with the Leipzig Glossing Rules (LGR) in the XML-based programme ELAN, as well as the CMDI profile BLAM for metadata, which was developed by the LAC as part of CLARIN to describe audiovisual language data in particular.
edition humboldt digital
The project “Alexander von Humboldt on his travels – Science in Motion” of the Berlin-Brandenburg Academy of Sciences and Humanities (BBAW) includes the complete edition of Alexander von Humboldt’s manuscripts on the theme of travel at the intersection of cultural and natural sciences. The corpus of the projected edition includes travel journals, diaries, memoranda, publications in the countries and regions visited, and correspondence.
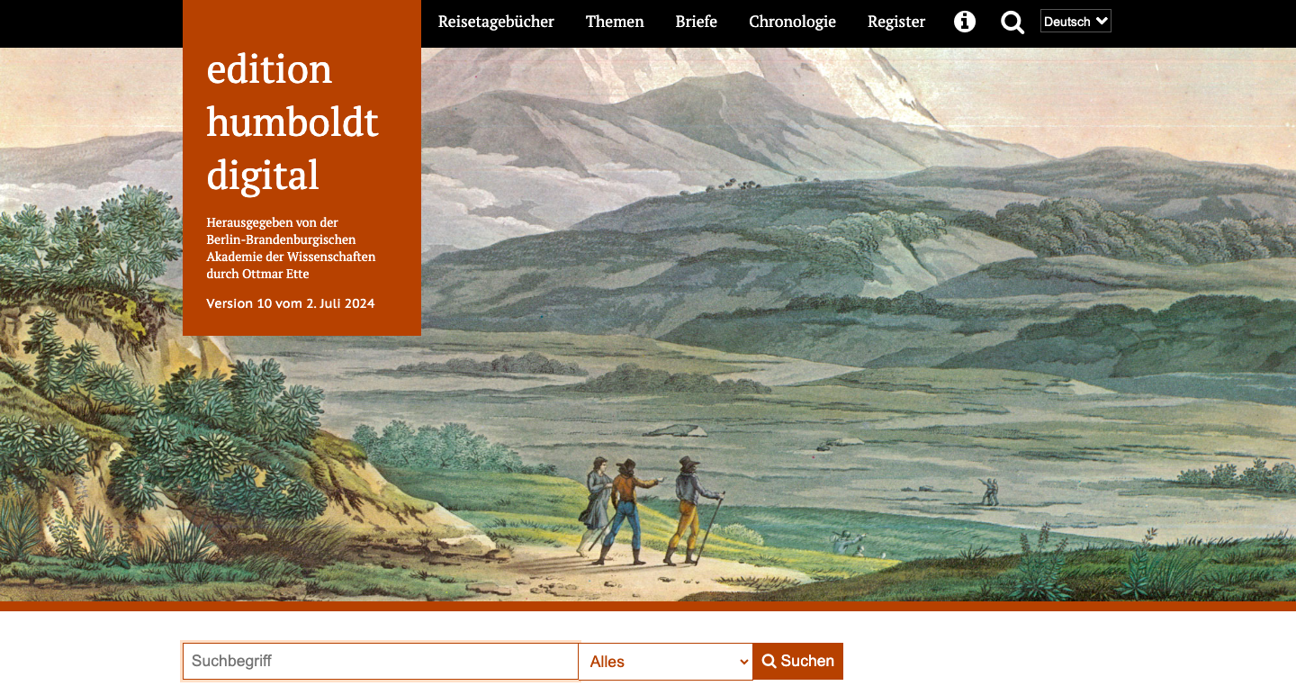
edition humboldt digital works with the DTA Base Format (DTABf) and the Integrated Authority File (GND), as well as a variety of other established standards and tools.
Klaus Mollenhauer Complete Edition (KMG)
The “Klaus Mollenhauer Complete Edition” (Link to Digital Edition to follow after publication) is a text-critical and annotated edition of the writings of educational scientist Klaus Mollenhauer (1928–1998). It includes both a digital edition and a printed and open-access book version with an apparatus.
The joint project works with TextGrid and uses TEI (Text Encoding Initiative) for text markup and LIDO (Lightweight Information Describing Objects) for object description. Further standards and tools used are described here.
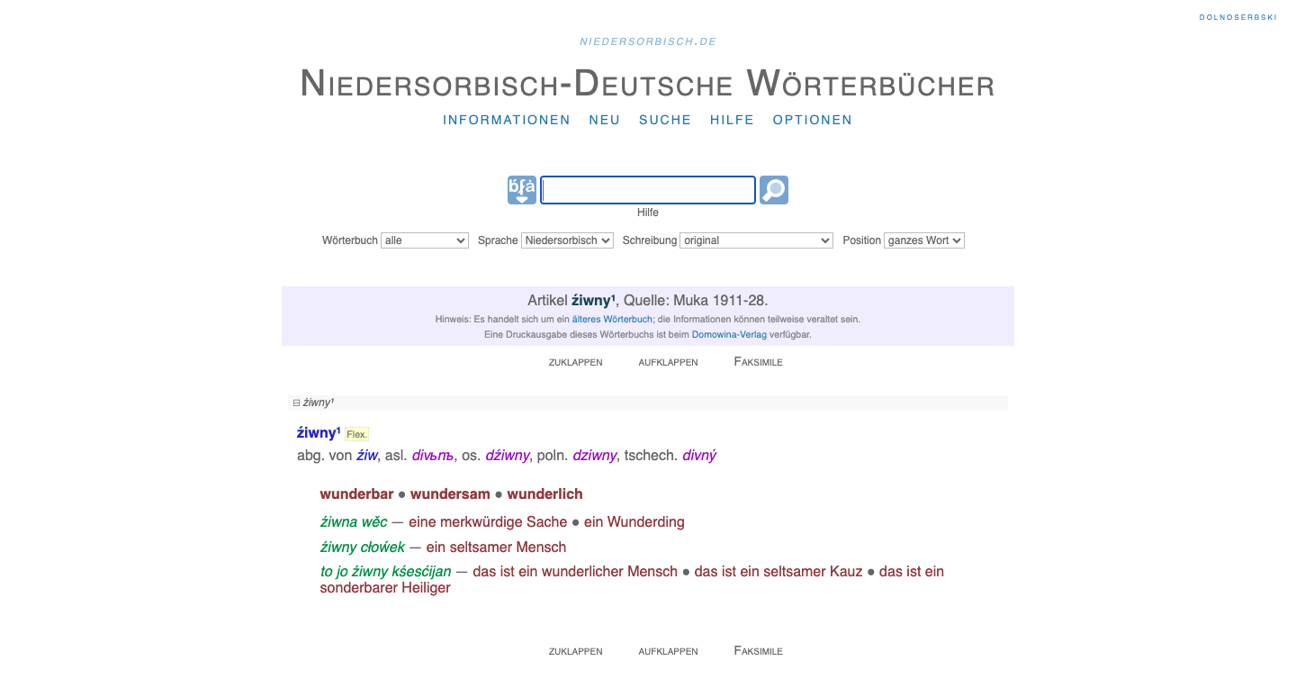
Text+ Cooperation Project INSERT
As part of the Text+-funded cooperation project “Integration of Lower Sorbian-German Dictionaries as Lexical Resources in Text+ (INSERT)”, four of the most important Lower Sorbian-German dictionaries, which the Sorbisches Institut already provides online, were integrated into the digital infrastructures of Text+ at the Saxon Academy of Sciences.
To do this, the existing XML data were first converted into the standard format TEI Lex-0 and then incorporated into the repository of the Saxon Academy of Sciences in Leipzig (SAW), one of the Text+ data centers for lexical resources, and into the Federated Content Search (FCS) of Text+.
Additional Application Examples
The Text+ Registry lists numerous other corpora and text collections, editions, and lexical resources in addition to the examples mentioned here.