The Text+ consortium in Göttingen's Pauliner church at the 2023 plenary meeting; photo: Martin Liebetruth
Structure of Text+
Text+ is a consortium of the National Research Data Infrastructure (NFDI) in Germany and is designed for all researchers working with text and language data in the broadest sense, including but not limited to linguistics, literary studies, philologies, including the so-called ‘small disciplines,’ philosophy, as well as language- and text-based research in the social sciences and political science.
Work Areas in Text+
Text+ is divided into various task areas. The Collections, Lexical Resources, and Editions task areas represent the data domains that Text+ initially focuses on. The data within these data domains have a long tradition in humanities research and are linked to sophisticated methodological paradigms, each requiring characteristic but also interdisciplinary practices of data generation, utilization, analysis, networking, and curation. These three data domains are also fundamental for interdisciplinary research practices in hermeneutics, palaeography, genealogy, edition philology, lexicography, computer philology, and computer linguistics.
The name Text+ conveys that this initiative focuses on typically text-based digital research data that are heterogeneous concerning language spaces (also beyond Europe) and modalities of language and writing systems. The plus sign indicates that language-based resources also encompass resources and tools for spoken language and multimodal data.
In addition to these data domains, there are the work areas of Infrastructure/Operations and Project Coordination. The Infrastructure/Operations area covers technical foundations, such as interfaces and shared technical solutions. Overall coordination addresses overarching aspects and the administration of the entire project.
Text+ as Part of the National Research Data Infrastructure (NFDI)
Text+ operates within the NFDI. Participants in Text+ are part of all committees and working groups of the NFDI.
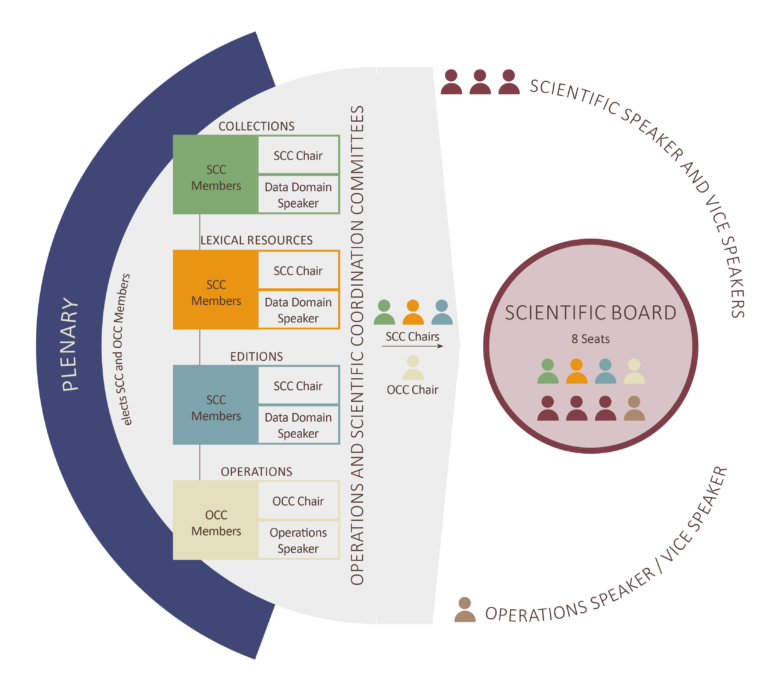
Governance
At the core of Text+’s governance is the shared responsibility of infrastructure and community, as well as cooperation across disciplinary boundaries. The listed boards are tasked with continuously evaluating Text+’s portfolio of data, tools, and services and driving its development in collaboration with the community.
The Scientific Board holds the scientific leadership of the consortium and decides on portfolio development.
The Steering Committee is responsible for implementing the work program and takes charge of the professional and financial monitoring of ongoing work. The Overall Coordination, consisting of Scientific and Operations Speakers, is the link between these committees and is responsible for consortium management and office leadership.
The leaders of the (co-)applying institutions form the Management Group. It supports the Steering Committee and Overall Coordination in overarching and strategic matters.
As a Representative for the Directorate of the State and University Library Göttingen
Coordination Committees
The Coordination Committees consist of three different Scientific Coordination Committees, each responsible for one of the data domains (Collections, Editions, Lexical Resources), and an Operations Coordination Committee. Their task is to continuously evaluate and expand the portfolio of data, tools, and services. The Coordination Committees consist of experts from the respective (subject) domains.