Forschungsdatenmanagement
Was sind Forschungsdaten?
Im Forschungsprozess kommen Daten in vielen unterschiedlichen Zusammenhängen vor. Forschungsdaten sind dabei einerseits die Ergebnisse von Forschung. Forschungsdaten sind andererseits aber auch alle Daten, die im Zuge wissenschaftlichen Arbeitens entstehen, also auch Zwischenprodukte im Forschungsverlauf hin zu den Forschungsergebnissen. Dazu zählen z.B. Beobachtungen, Experimente, Simulationsrechnungen, Erhebungen, Befragungen, Quellenforschungen, Aufzeichnungen, Digitalisierung, Auswertungen und auch projektspezifische, individuelle Zusammenstellungen bestehender Daten (vgl. Rat für Informationsinfrastrukturen. (2019). Herausforderung Datenqualität – Empfehlungen zur Zukunftsfähigkeit von Forschung im digitalen Wandel, S. B-3.)
Forschungsdaten in Text+
Auch in den Datendomänen von Text+ entstehen vielfältige Forschungsdaten; man denke an
- individuelle Textkorpora, Textannotationen, Interviews, Transkriptionen, Sensordaten, Umfragen, usw. (Collections)
- Übersetzungen, Terminologien, Wortnetze, Wortlisten, usw. (Lexical Resources)
- OCR-Dateien, Handschriften und deren Transkriptionen, Textapparate, usw. (Editions)
Ein konkretes Beispiel ist das Korpus „Briefe von Jean Paul“ (Bereich Collections, Editions und Lexical Resources) mit insgesamt 5.004 Briefen. Diese stammen aus einer digitalen Edition, welche auf Grundlage der per Double-Keying-Verfahren retrodigitalisierten gedruckten Edition erstellt wurde. Die Briefe sind – orientiert am Basisformat des Deutschen Textarchivs – in TEI XML kodiert, mit Metadaten und Normdaten versehen sowie mit einer historisch-kritischen Ausgabe verknüpft. Die unter offener Lizenz veröffentlichten Forschungsdaten des Korpus können vielfach nachgenutzt werden, so bspw. als Belegressource bei der Wörterbucharbeit.
Ein anderes Beispiel ist die Sammlung „Digitalisierte Inhaltsverzeichnisse“ (TA Collections) der Deutschen Nationalbibliothek. Sie besteht aus über 2,3 Millionen Inhaltsverzeichnissen von Büchern, die seit 1913 v.a. in Deutschland erschienen sind und als Grundlage für weitere Forschung dienen können.
Schließlich sind auch die Daten zu den Text+ User Stories zu nennen. Diese liegen als einzelne Volltexte vor, als Datengrundlage zur zugehörigen Publikation gibt es aber auch Tabellen mit Metadaten, Annotationen und Keywords zum Download und zur Weiterverarbeitung.
Worum geht es im FDM?
Forschungsdatenmanagement als Teil guter wissenschaftlicher Praxis
Das Forschungsdatenmanagement ist ein elementarer Bestandteil der guten wissenschaftlichen Praxis. Wissenschaftlerinnen und Wissenschaftler hinterlegen ihre Publikationen soweit möglich immer mit Forschungsdaten in verbreiteten und interoperablen Formaten, um Nachvollziehbarkeit, Anschlussfähigkeit der Forschung und Nachnutzbarkeit zu garantieren. Die Ablage der Daten in Archiven und Repositorien erfolgt gemäß der FAIR-Prinzipien („Findable, Accessible, Interoperable, Re-Usable“). Siehe dazu auch die Leitlinien zur Sicherung guter wissenschaftlicher Praxis der Deutschen Forschungsgemeinschaft (DFG). Die einzelnen Prozessphasen, die Forschungsdaten während ihrer Erhebung, Weiterverarbeitung und Archivierung durchlaufen, werden im Forschungsdatenlebenszyklus veranschaulicht:
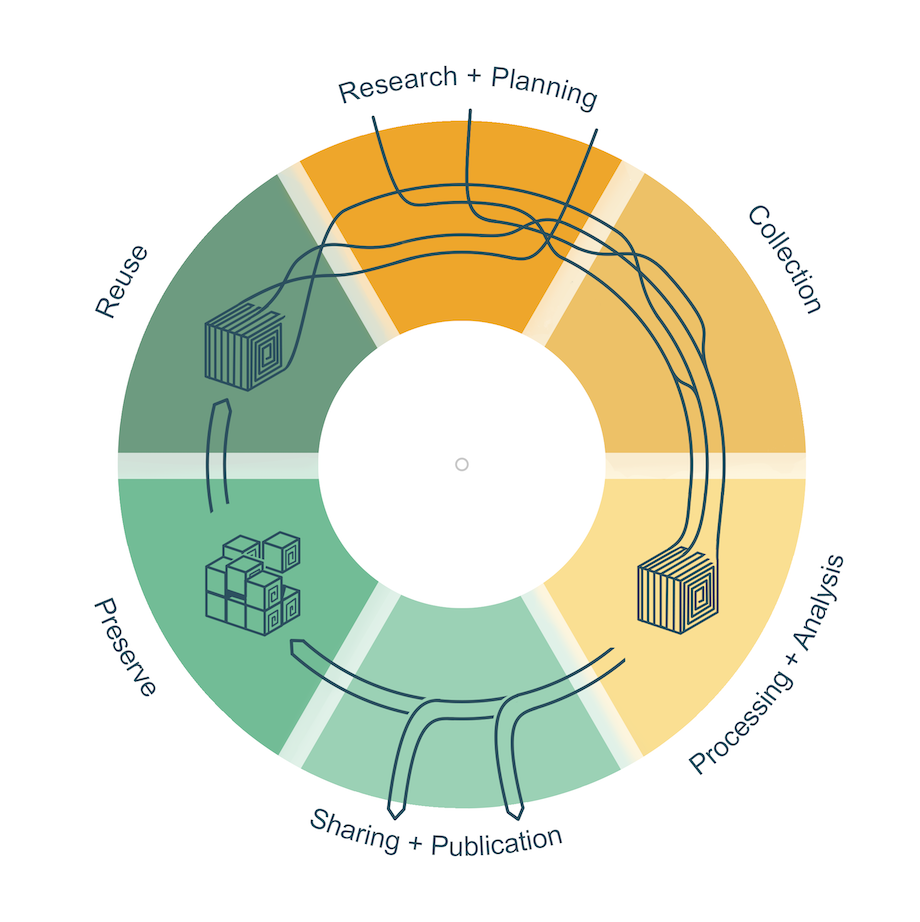
Weshalb ist Forschungsdatenmanagement für Sie relevant?
In Kürze:
Nutzen für Sie
Durchdachtes Forschungsdatenmanagement sorgt bereits von Forschungsbeginn an für effizientes Arbeiten, vermeidet Mehrarbeit, beugt Datenverlust vor und sorgt für hohe Datenqualität. Es ermöglicht das niedrigschwellige Teilen von Daten innerhalb des eigenen Forschungskreises und darüber hinaus. Forschungsdatenmanagement ist Voraussetzung von Data Journals, begünstigt also Data Publications und erhöht so die eigene Zitationszahl und wissenschaftliche Reputation. Und nicht zuletzt ist Forschungsdatenmanagement eine Grundlage guter wissenschaftlicher Praxis (siehe Deutsche Forschungsgemeinschaft. (2022). Leitlinien zur Sicherung guter wissenschaftlicher Praxis. DOI: 10.5271/zenodo.6472827).
Nutzen für andere
Forschungsdaten, die im Zuge von transparentem Forschungsdatenmanagement entstanden sind und auf anerkannte (Meta)Datenformate zurückgreifen, sind interoperabler und dadurch nachnutzbarer, sowohl innerhalb des eigenen Forschungskreises als auch von extern. Das begünstigt deren Weiterverarbeitung und dient so der Förderung weiterer Forschung.
Nutzen für die Projektförderung
Die DFG hält zum Thema Grundlagen und Rahmenbedigungen von Projektförderung in Bezug auf Forschungsdaten fest: „Grundsätzlich müssen in allen Förderprogrammen, in denen ein konkretes Arbeitsprogramm für ein Forschungsvorhaben beschrieben wird, Ausführungen zum Umgang mit Forschungsdaten beschrieben werden.“
Leitfragen
- Welche Forschungsdaten wollen Sie erheben oder für Ihre Forschungsfrage verwenden?
- Haben Sie bereits ein Konzept zur Strukturierung Ihrer Daten oder haben sie bereits einen FDP-Plan?
- Verfolgen Sie bereits ein nachhaltiges Datensicherungskonzept (Backup) oder suchen Sie nach Möglichkeiten, dies über vertrauenswürdige Partner zu implementieren?
- Welche Konzepte zur Zitierbarkeit Ihrer Forschungsdaten planen Sie, um Ihr wissenschaftliches Arbeiten zu dokumentieren und die Daten nachnutzbar zu machen?
- Kennen Sie die Lizenzen, unter denen die von Ihnen verwendeten Daten stehen?
- Welche Vorgaben macht Ihr Förderer bezüglich einer Dokumentation zum Umgang mit Ihren Daten?
- Falls Sie planen, Referenzdaten und Daten Dritter einzusetzen, wie werden Sie die Daten erhalten und unter welchen Bedingungen dürfen Sie die Daten nutzen?
Die Beantwortung dieser Fragen ist zentraler Teil der Planung des Forschungsdatenmanagements (FDM). Text+ unterstützt Sie dabei, Ihre Forschungsdaten zu verwalten, zu speichern (siehe die Liste der Datenzentren in Text+) und entlang der FAIR-Prinzipien nachnutzbar zu machen, hilft Ihnen bei der Erstellung von FDM-Plänen und steht jederzeit beratend zur Seite.
FDM-Unterstützung durch Text+
Forschende werden von Beginn des Forschungsprozesses an bei allen Schritten des Datenmanagements von den antragstellenden und an Text+ beteiligten Institutionen mit ihren zertifizierten Datenrepositorien entsprechend ihres institutionellen Auftrags und ihres Fachwissens unterstützt. Auch die FAIRification von Bestandsdaten gehört zum Angebotsportfolio. Jahrelange fundierte Erfahrungen zu den besonderen sprach- und textbasierten Anforderungen an das Forschungsdatenmanagement, wie bspw. unterschiedliche Metadatenformate, Urheberrechtsanforderungen usw. sowie mit Aufbau und Betrieb einer ortsverteilten Infrastruktur sind bei allen Institutionen vorhanden.
Weitere Informationen und Werkzeuge zum FDM
Tools
Zur Unterstützung beim FDM gibt es verschiedene Tools, die anhand von Fragen wichtige FDM-Elemente aufzeigen und bei der Erstellung eines FDM-Plans helfen:
- RDMO: ausführliche, von der Community entwickelte allgemeine Fragensammlung zum Forschungsdatenmanagement
- RDMO-Instanz mit dem Text+ Fragenkatalog beim Text+ Partner Göttinger Research Online
- argos: europäisches Datenmanagementtool von OpenAIRE
- DMP-online des Digital Curation Centres in Großbritannien
RDMO
Wir – die an Text+ beteiligten Institutionen – beraten Forschende von Beginn des Forschungsprozesses an bei allen Schritten der systematischen Organisation ihrer Forschungsdaten. Dabei stützen wir uns auf das Fachwissen unserer zertifizierten Datenrepositorien. Zur Orientierung in diesem Prozess und zur Dokumentation der Forschungsdaten in Form eines Datenmanagementplans bietet Text+ einen Fragenkatalog an, der sich eng am Standardkatalog des Research Data Management Organiser (RDMO) orientiert. Als Grundlage für den Text+ Fragenkatalog dient der Fragenkatalog der Max Weber Stiftung “MWS Ersterfassung”. Der Text+ RDMO-Fragenkatalog wurde in Zusammenarbeit mit Beteiligten des Text+ Konsortiums angepasst und mit disziplinspezifischen Beispielen erweitert. Hierbei handelt es sich um einen ersten Entwurf, der sukzessiv überarbeitet und erweitert wird und als nachnutzbarer XML-Katalog hier (GRO.plan der eResearch Alliance der SUB Göttingen) eingebunden ist.
Der Fragenkatalog ist eng mit unserem Beratungsangebot verknüpft. Forschende können eigenständig oder im Rahmen einer begleitenden Beratung durch den Text+ Helpdesk den Fragenkatalog ausfüllen und sich im direkten Austausch mit den Problemstellungen, die er potentiell eröffnet, auseinandersetzen. Der Fragenkatalog dient dabei der Selbstorganisation, soll aber auch für den Umgang mit Forschungsdaten sensibilisieren und die Arbeit mit ihnen erleichtern. Das von Text+ bereitgestellte Angebot richtet sich explizit an unsere Community, die sich schwerpunktmäßig mit sprach- und textbasierten Daten beschäftigt. Zu den Nutzungsszenarien zählen Antragsstellungen für Projekte, die Vorbereitung für die (langfristige) Speicherung von Forschungsdaten in entsprechenden Repositorien und die grundsätzliche Organisation von Forschungsdaten.
Literatur und Links
Auf folgenden Seiten können Sie sich weiter zum Thema FDM informieren. Die genannten Seiten stellen dabei nur eine Auswahl des immensen Informationsangebots dar, das online und gedruckt existiert.
- überblicksartige Handreichung der Arbeitsgruppe Forschungsdaten der Schwerpunktinitiative „Digitale Information“ der Allianz der deutschen Wissenschaftsorganisationen von 2018
- forschungsdaten.info: umfangreiche, ständig erweiterte Informationsplattform mit zahlreichen ausgewählten Informationen; durchsuchbar z.B. nach Wissenschaftsbereich, z.B. Geisteswissenschaften; nach Schlagworten im Glossar; nach FDM-Themen
- Liste der FDM-Services der DHd-AG Datenzentren
Weitere, teils fachspezifischere Informationen finden sich beispielsweise bei vielen Fachinformationsdiensten, auf den Seiten der Landesinitiativen FDM sowie bei zahlreichen Universitäten, Bibliotheken, Akademien und weiteren außeruniversitären Forschungseinrichtungen sowie außerdem beim Rat für Informationsinfrastrukturen, der DINI/nestor-AG Forschungsdaten und auch auf Seiten von DFG und BMBF.
Kontakt zu unserem FDM-Team im Text+ Helpdesk! Der Text+ Helpdesk steht für Sie gerne zu jeglichen Fragen des FDM zur Verfügung, insbesondere zu den drei Datendomänen Sammlungen, Lexikalische Ressourcen und Editionen, aber auch zu Infrastruktur, rechtlichen und ethischen Fragen.