Anwendungsbeispiele
In den unten beschriebenen Vorhaben aus den Text- und Sprachwissenschaften werden von Text+ empfohlene Standards und standardbasierte Tools erfolgreich eingesetzt. Es wird in der ersten Jahreshälfte 2025 dazu auch eine Workshopreihe angeboten, in der die Anwendungsbeispiele vorgestellt und diskutiert werden können. Die Veranstaltungen werden zu gegebener Zeit auch auf dieser Seite verlinkt werden.
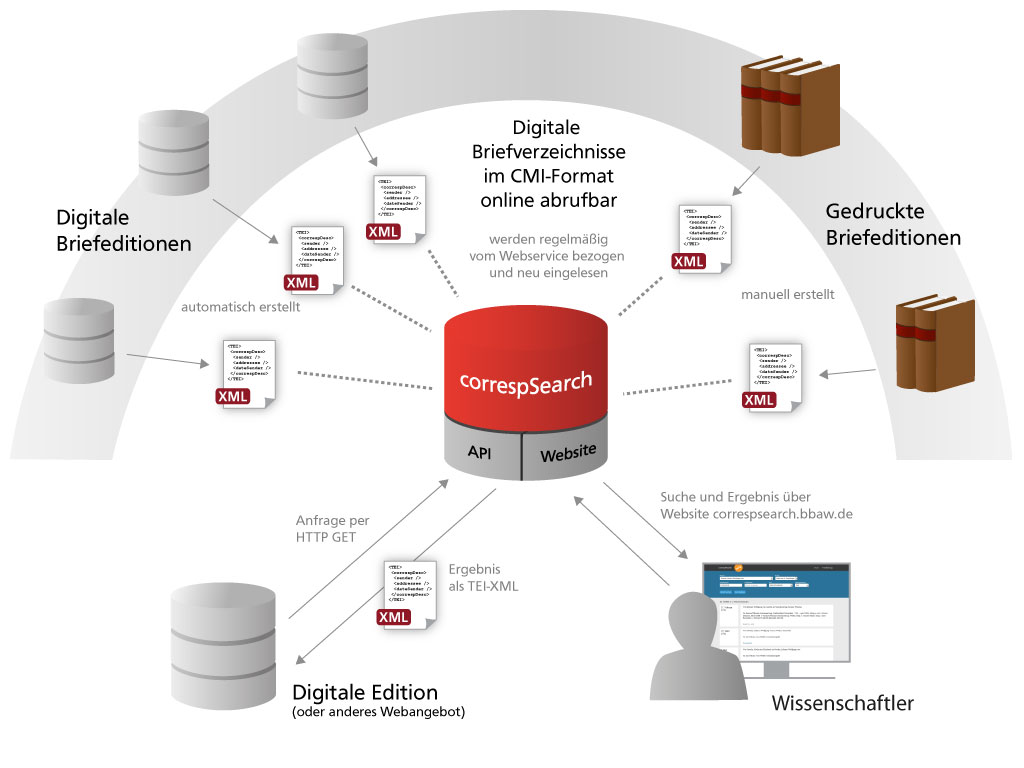
correspSearch – Briefeditionen durchsuchen und vernetzen
Der Webservice „correspSearch” der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) aggregiert aus verteilten Editionen und Repositorien Briefmetadaten und stellt sie über offene Schnittstellen unter einer freien Lizenz zentral zur Verfügung. So können Verzeichnisse verschiedener digitaler und gedruckter Briefeditionen nach Absender, Empfänger, Schreibort und -datum durchsucht werden.
Grundlage des Webservices „correspSearch“ sind im Correspondence Metadata Interchange (CMI) Format online bereitgestellte digitale Briefverzeichnisse. Das CMI-Format basiert wesentlich auf der Erweiterung „correspDesc“ (Correspondence Description) für die Richtlinien der Text Encoding Initiative (TEI). Das Element correspDesc wurde von der TEI Correspondence SIG entwickelt, um die Korrespondenz-spezifischen Metadaten von Briefen, Postkarten etc. in TEI-basierten Editionen notieren zu können.
Das Deutsche Referenzkorpus (DeReKo)
Die Korpora geschriebener Gegenwartssprache des Leibniz-Instituts für Deutsche Sprache (IDS) bilden die weltweit größte linguistisch motivierte Sammlung elektronischer Korpora mit geschriebenen deutschsprachigen Texten aus der Gegenwart und der neueren Vergangenheit. Sie enthalten belletristische, wissenschaftliche und populärwissenschaftliche Texte, eine große Zahl von Zeitungstexten sowie eine breite Palette weiterer Textarten.
Für die effiziente automatische Auswertung großer elektronischer Textsammlungen müssen die Texte in einem einheitlichen Datenstrukturformat kodiert sein. Für die Korpora geschriebener Sprache am IDS ist dieses Format das so genannte IDS-Textmodell, basierend auf TEI (Text Encoding Initiative).
Deutsches Textarchiv (DTA)
Das Deutsche Textarchiv (DTA) der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) stellt eine disziplinen- und gattungsübergreifende Auswahl deutschsprachiger Texte mit einem Publikationsschwerpunkt in der Zeit um 1600 bis 1900 als linguistisch annotiertes Volltextkorpus bereit.
Das DTA legt großen Wert auf eine sehr hohe Erfassungsgenauigkeit, die strukturelle und linguistische Erschließung der Textdaten sowie die Verlässlichkeit der Metadaten. Ein wichtiges Instrumentarium bei der Entwicklung des Korpus war die Etablierung eines einheitlichen Formates, des DTA-Basisformats (DTABf) auf der Grundlage von TEI (Text Encoding Initiative). Das DTA-Basisformat wird von der DFG zur Nachnutzung empfohlen.
Die Beria-Collection
Die Beria-Collection umfasst eine Auswahl von 12 Texten des Beria-Korpus. Beria – in der Literatur auch unter dem Exonym Zaghawa bekannt – ist eine Sprache, die im Darfur, im Grenzgebiet zwischen Sudan und Tschad gesprochen wird (Nilo-Saharanisch, 315.000 Sprecher). Die ausgewählten Texte stammen von zwei erwachsenen Männern, die den sudanesischen Dialekt Wagi sprechen. Sie liegen im Sprachenarchiv Köln (LAC, Link zum Online-Zugang folgt nach Veröffentlichung) digital im Audio-Video-Format vor und werden im Rahmen des Projekts vollständig transkribiert, übersetzt, zeitaligniert annotiert und mit detaillierten linguistischen Informationen in Form von interlinearen Glossen versehen.
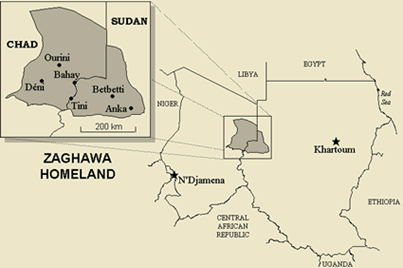
Ziel ist es, ein maschinenlesbares und durchsuchbares Textkorpus aus einer oralen, außereuropäischen und wenig beschriebenen Kultur in das Text+ Portfolio zu integrieren. Aktuell wird in einem vorgeschalteten Zusatzschritt ein digitales Lexikon erstellt, das das Textkorpus ergänzen wird. Es werden Standards der allgemeinen Linguistik, wie sie für Sprachdokumentationskorpora durch die QUEST-Richtlinien formuliert wurden, verwendet, darunter linguistische Annotationen in IPA und gemäß den Leipzig Glossing Rules (LGR) im XML-basierten Programm ELAN sowie für Metadaten das CMDI-Profil BLAM, das vom LAC im Rahmen von CLARIN zur Beschreibung insbesondere audiovisueller Sprachdaten entwickelt wurde.
edition humboldt digital
Das Vorhaben „Alexander von Humboldt auf Reisen – Wissenschaft aus der Bewegung“ der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) umfasst die vollständige Edition der Manuskripte Alexander von Humboldts zum Themenkomplex Reisen an der Schnittstelle von Kultur- und Naturwissenschaften. Das Korpus der projektierten Edition beinhaltet Reisejournale, Tagebücher, Denkschriften, Publikationen in den bereisten Ländern und Regionen sowie Korrespondenzen.
edition humboldt digital arbeitet mit dem Basisformat des Deutschen Textarchivs (DTABf) und der Gemeinsamen Normdatei (GND) und setzt darüberhinaus eine Vielzahl weiterer etablierter Standards und Tools ein.
Klaus Mollenhauer Gesamtausgabe (KMG)
Die „Klaus Mollenhauer Gesamtausgabe“ (Link zur Digitalen Edition folgt nach Veröffentlichung) ist eine textkritische und kommentierte Edition der Schriften des Erziehungswissenschaftlers Klaus Mollenhauer (1928–1998). Sie umfasst sowohl eine digitale Edition als auch eine gedruckte und im Open Access zugängliche Buchfassung mit Apparat.
Das Verbundprojekt arbeitet mit TextGrid und setzt u.a. TEI(Text Encoding Initiative) für die Auszeichnung der Texte und LIDO (Lightweight Information Describing Objects) für die Beschreibung von Objekten ein. Weitere verwendete Standards und Tools werden hier beschrieben.
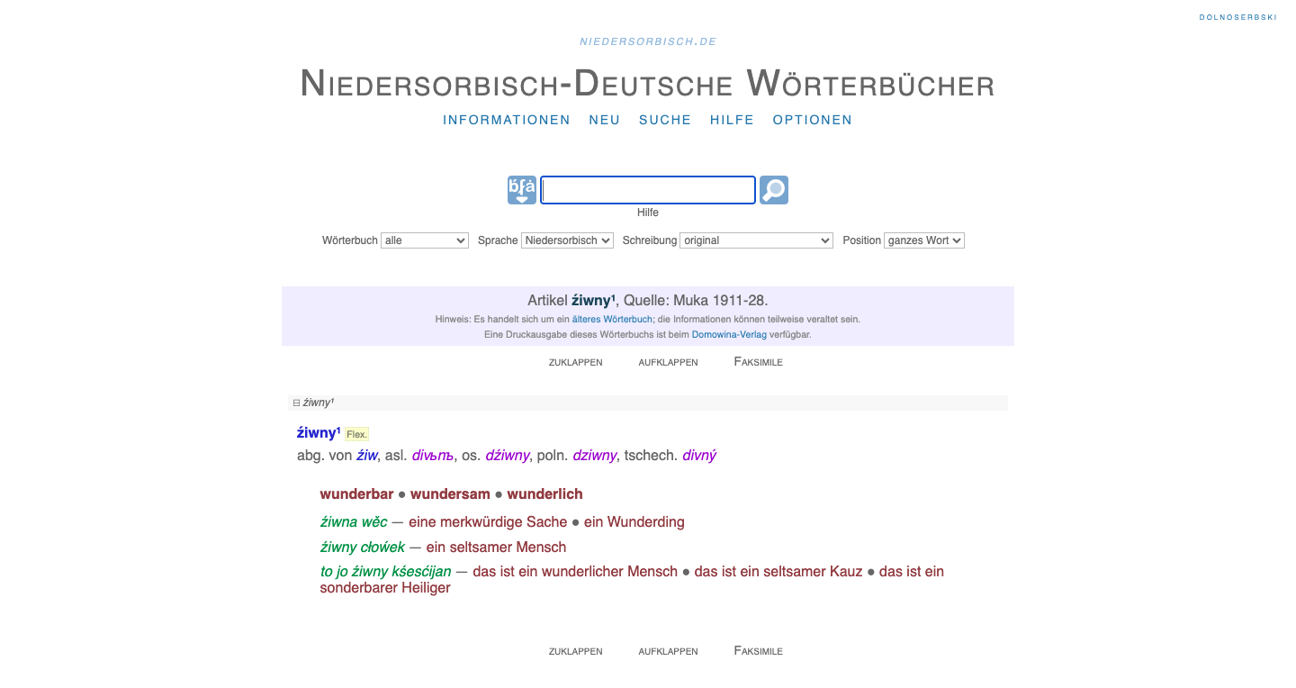
Text+ Kooperationsprojekt INSERT
Im Rahmen des von Text+ geförderten Kooperationsprojekts „Integration niedersorbisch-deutscher Wörterbücher als lexikalische Ressourcen in Text+ (INSERT)“ wurden an der Sächsischen Akademie der Wissenschaften vier der wichtigsten niedersorbisch-deutschen Wörterbücher, die das Sorbische Institut bereits online zur Verfügung stellt, in die digitalen Infrastrukturen von Text+ integriert.
Dazu wurden die bereits vorhandenen XML-Daten zunächst in das Standardformat TEI Lex-0 übersetzt und anschließend in das Repositorium der Sächsischen Akademie der Wissenschaften zu Leipzig (SAW), eines der Text+ Datenzentren für lexikalische Ressourcen, und in die Föderierte Inhaltssuche (FCS) von Text+ aufgenommen.
Weitere Anwendungsbeispiele
Die Text+ Registry verzeichnet neben den hier genannten Beispielen eine Vielzahl weiterer Korpora und Textsammlungen, Editionen sowie lexikalischer Ressourcen.