A modern mobile application for lexical resources of under-resourced languages
Simon Kaleschke (Universität Leipzig)
Motivation
As a user, I own a smartphone. In recent years, the market for smartphones has experienced rapid growth. Now, billions of people all over the world own smartphones. These devices bring with them a wide variety of mobile applications and provide access to educational resources even in under-developed regions of the world. As many services and information providers inevitably find their way onto the users’ mobile phones, I also start seeing dictionaries pop up in app stores. A dictionary app seems to be the modern access strategy for dictionaries, extending the potential user and participant base significantly. I am more effective in using them, and I demand swiftness and high availability.
Thus, as a computational linguist (104-04) and a researcher in Language Processing (409-05), a new task for me is the provision of dictionary data to end-users in the form of mobile dictionary applications, and in turn further testing of their efficacy. While popular dictionaries, like the Oxford Dictionary of English, have already been established, dictionaries for lesser-known and under-resourced languages still need to be integrated into the growing ecosystem. The datasets are mostly small and consist of a wide variety of formats. At the moment, there is no easy way for me to publish my datasets via these new platforms.
Objectives
The Android-based mobile application Balalaika provides a way to publish lexical resources, especially for under-resourced languages, developed together with users and lexicographers. The app has been designed for the inclusion of a variety of datasets and formats, by using a simple mediator data format. The developers already have experience in the integration of these kinds of heterogeneous datasets, and first case studies have been conducted in the context of CLARIN-D for languages of the Bantu language family, together with external partners from South Africa, including partners from the South Africa Centre for Digital Language Resources (SADiLaR).
Using this application, I can share my dictionary datasets and associated lexical resources with other scientists and end-users, like language learners and especially native speakers. I either work with the developers to integrate new dictionaries into the existing application or I create a stand-alone mobile app, which only holds my own dictionaries, using the open-source codebase. This way, I get an easy way to share my data with a wide public audience, which in turn may help in testing the efficacy and veracity of my dictionaries.
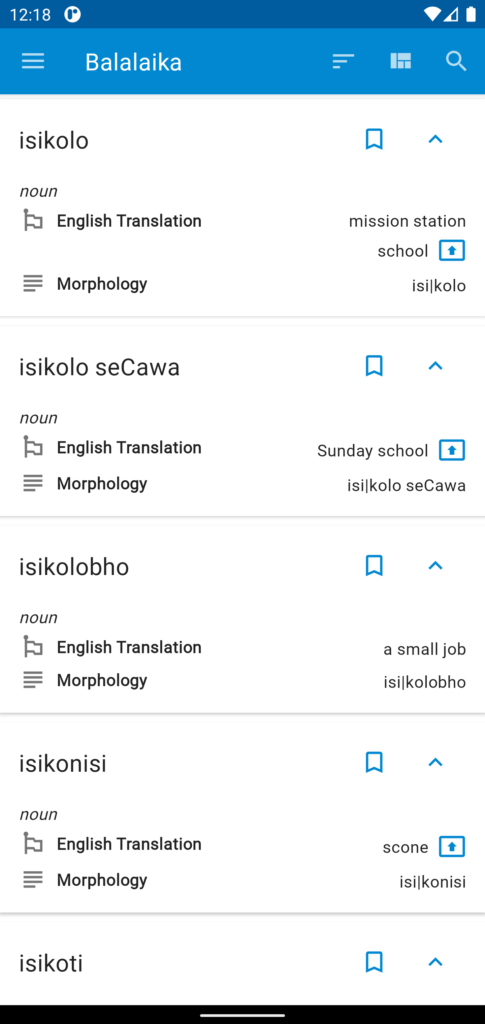
Screenshot App “Balalaika”Main dictionary view. Entries are shown consecutively, can be saved as bookmarks and provide context actions.
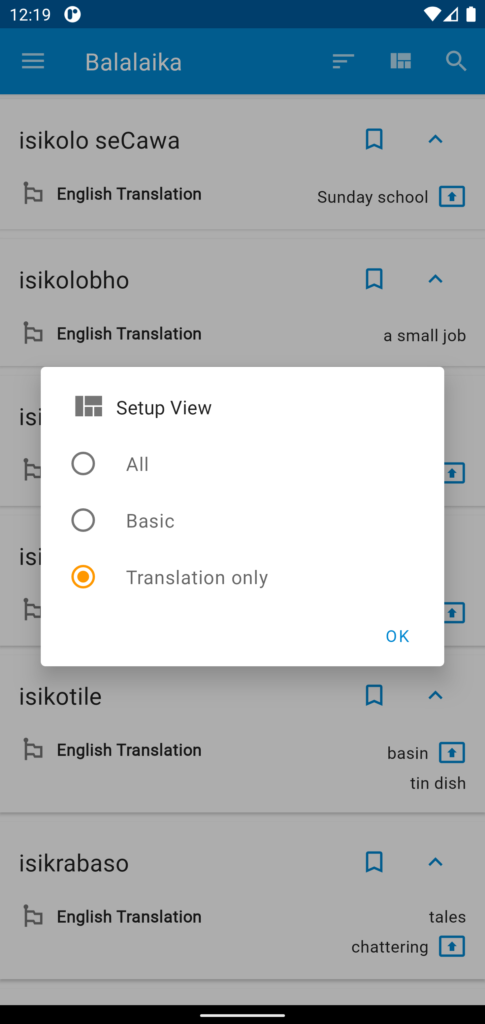
Screenshot App “Balalaika”The amount of information shown can be configured by the user, based on their preferences and work tasks.
Screenshot App “Balalaika”The dictionary can be searched for keywords. Previous searches are saved and can be repeated later.
Screenshot App “Balalaika”Various dictionaries can be downloaded from a variety of sources.
Screenshot App “Balalaika”Detailed information about a single dictionary.
Solution
The application relies on the established infrastructure developed in CLARIN. This includes the long-term hosting and archiving of lexical data, the use of persistent identifiers, the integration of the application in a distributed and service-oriented research architecture and the support of interested researchers by a CLARIN competence centre.
The mobile app handles a wide variety of dictionary data sets and related lexical resources. The developers implement and maintain a set of conversing schemes for existing data sets and popular dictionary data formats (e. g. RDF, LMF, TEI Lex-0), which help me in transforming my datasets for use in the application. Datasets can be hosted on a server or delivered with the app itself. Improvements and new features are developed to satisfy the needs of a large number of user-profiles with different work tasks, based on feedback by me and end-users.
Challenges
There are, at the moment, no comparable open mobile applications. The application is very recent and has so far only been tested in some case studies. Maintenance and bugs fixes will be necessary (very likely), and the flexible layout of the application might be inferior to a custom-tailored solution (likely). Data set conversion can take some time to develop and may include some manual labour to clean up data sets (to be determined). The long-term user acceptance is currently unclear since end-users have not yet been involved in the case studies.
Review by community
Balalaika has been published at an international conference for under-resourced languages and received positive interest and diverse feedback. In the future, it is planned to further establish close contact with users and scientists to determine the prospective development of the application. Feedback will influence the look and feel of the app as well as which new formats will be supported out-of-the-box.